
OpenAI's o1 model
[Article: Learning to Reason with LLMs]

Summary by Adrian Wilkins-Caruana
The folks at OpenAI have been hard at work iterating on their flagship LLM, GPT-4. While its successor, dubbed o1, isn’t quite ready for prime time yet, the company has made a preview version of it, o1-preview, available for use in ChatGPT and to some API users. We’re going to compare o1-preview’s performance to GPT-4 and take a look at how it works.

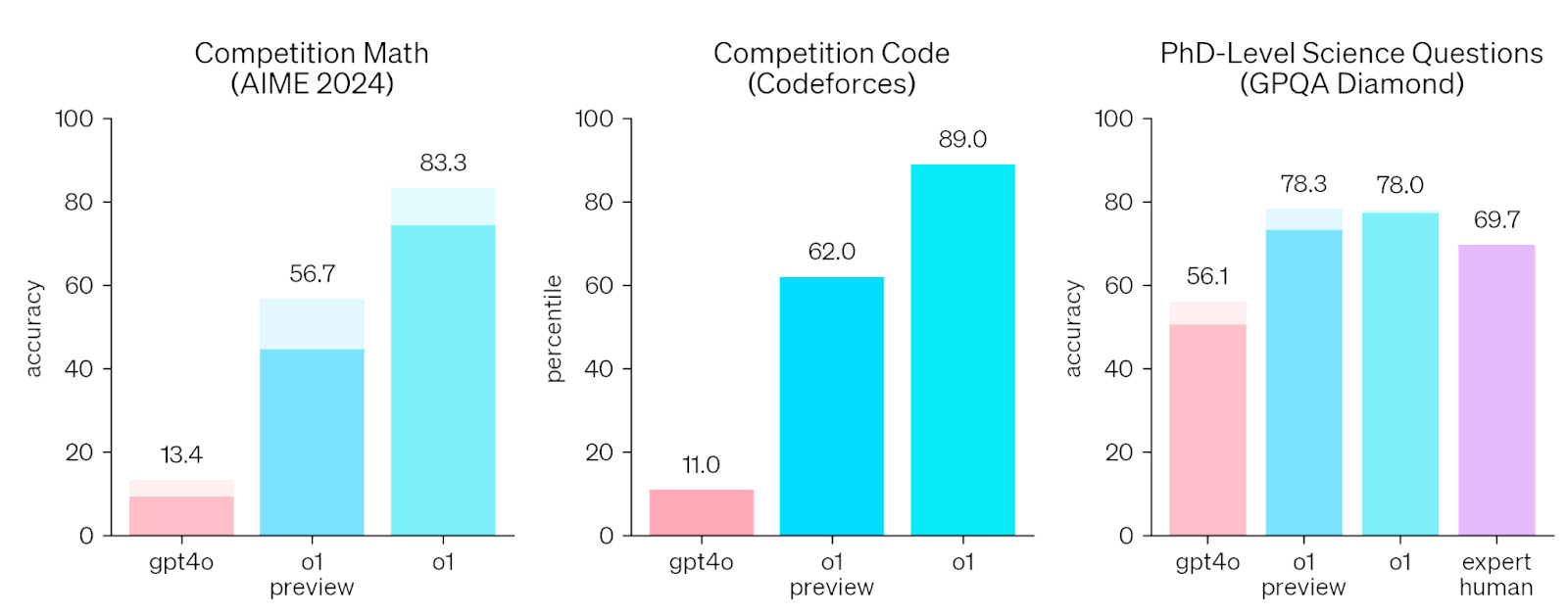
OpenAI is touting substantial improvements in accuracy on a number of tasks, including math, coding, and science, as well as on other AP and SAT exams. For example, the figure below compares o1 and o1-preview to GPT-4. The shaded bars indicate the consensus of 64 model results, while the solid bars indicate single-shot accuracy (i.e., on the model’s first output). The performance of o1 and o1-preview on these tasks is quite impressive, even surpassing human-level experts on the science questions! And o1’s improvements aren’t just limited to science and math knowledge — o1 also beats GPT-4 on English literature, global facts, public relations, professional law, and econometrics exams.
It seems that OpenAI has achieved these impressive results in two ways. The first is more training, specifically reinforcement learning. As opposed to standard self-supervised learning — which creates great next-word predictors — reinforcement learning is the special kind of training that’s used to make LLMs useful for things like conversations and problem solving. The second way was to give the LLM more time to think about its answers before providing them. The classic way to do this is using what’s known as a Chain of Thoughts, where the LLM solves a problem step by step. (We’ve covered a few other ways to do this on Learn and Burn; see our summaries on Tree of Thoughts and the more sophisticated Buffer of Thoughts approaches.) According to their own article, OpenAI seems to be using an approach called Chain of Thoughts (CoT). The figure below shows how o1’s accuracy scales with train- and test-time compute.

You might be wondering what o1’s thoughts look like. Here’s an example for a cipher-solving task:
oyfjdnisdr rtqwainr acxz mynzbhhx -> Think step by step
Use the example above to decode:
oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz
For this task, o1 thought about different hypotheses — it considered anagrams and letter substitutions — before realizing that the letter groups in the cypher text correspond to words in the decoded cypher, and that consecutive letter pairs correspond to decoded single letters (so two letters map down to one). o1 then noticed that half the sum of the alphabet positions (eg, a is 1, b is 2, etc.) for pairs of letters in the cypher text correspond to the alphabet positions of the decoded letters. So the letter-pair “oy” decodes to “t” since (15 + 25) / 2 = 20. This allowed o1 to successfully decode the cypher: there are three r’s in strawberry.
OpenAI says that they’re using CoT, but I think their approach deviates from the standard CoT approach from the original paper, which simply uses prompts to encourage the LLM to “think out loud” about its thought process. Instead, they say o1 learns to hone its chain of thought and refine the strategies it uses through reinforcement learning. I’m guessing that they mean that they use human feedback, but it’s not clear to me whether the humans provide feedback on just o1’s responses or on its thoughts, too. This is made even more opaque by OpenAI’s decision to hide o1’s thoughts from users; so it’s not clear whether they were also hidden from the people who provided o1 feedback during its training.
I think the CoT approach is a must-have for helping LLMs like o1 on advanced reasoning tasks, but I also reckon that, aside from simply scaling training and inference compute time, the o1 researchers also used many other clever tricks to eke more performance out of their LLM. For example, they might have paid close attention to curating higher-quality datasets or to eliminating any inconsistencies in their dataset of human feedback. This is just speculation though, and we can’t say much about o1 with any certainty — except for how impressive it is!