
Better LLM problem-solving without repeated prompting
[Paper: Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models]

Summary by Adrian Wilkins-Caruana
If you’ve ever used Google’s Gemini model, you might have noticed that sometimes it shows you the model’s “drafts,” which make it clear that Gemini isn’t a simple language-in, language-out LLM. It has a more complicated inference procedure that involves drafting before generating its final output. Processes like this drafting trick are a common way to improve an LLM’s accuracy and utility, but sometimes these approaches don’t improve the accuracy enough, or they make the model substantially less efficient. But a new approach called buffer of thoughts (BoT) is an accurate and efficient way to augment an LLM’s output that mimics the way people retrieve and refine their thoughts.

You might be familiar with some of the simpler augmentation processes, such as few-shot prompting or chain-of-thought (CoT) prompting. These approaches use a single query to prompt the LLM; sometimes this makes the LLM more accurate, but it’s not a silver bullet. More sophisticated processes use multiple queries to build a graph or tree of thoughts, iteratively refining and pruning the graph before reaching a final output. We covered the tree of thoughts (ToT) paper last year; give it a read if you haven’t already (link). The figure below shows these single- and multi-query processes, as well as the new BoT approach.
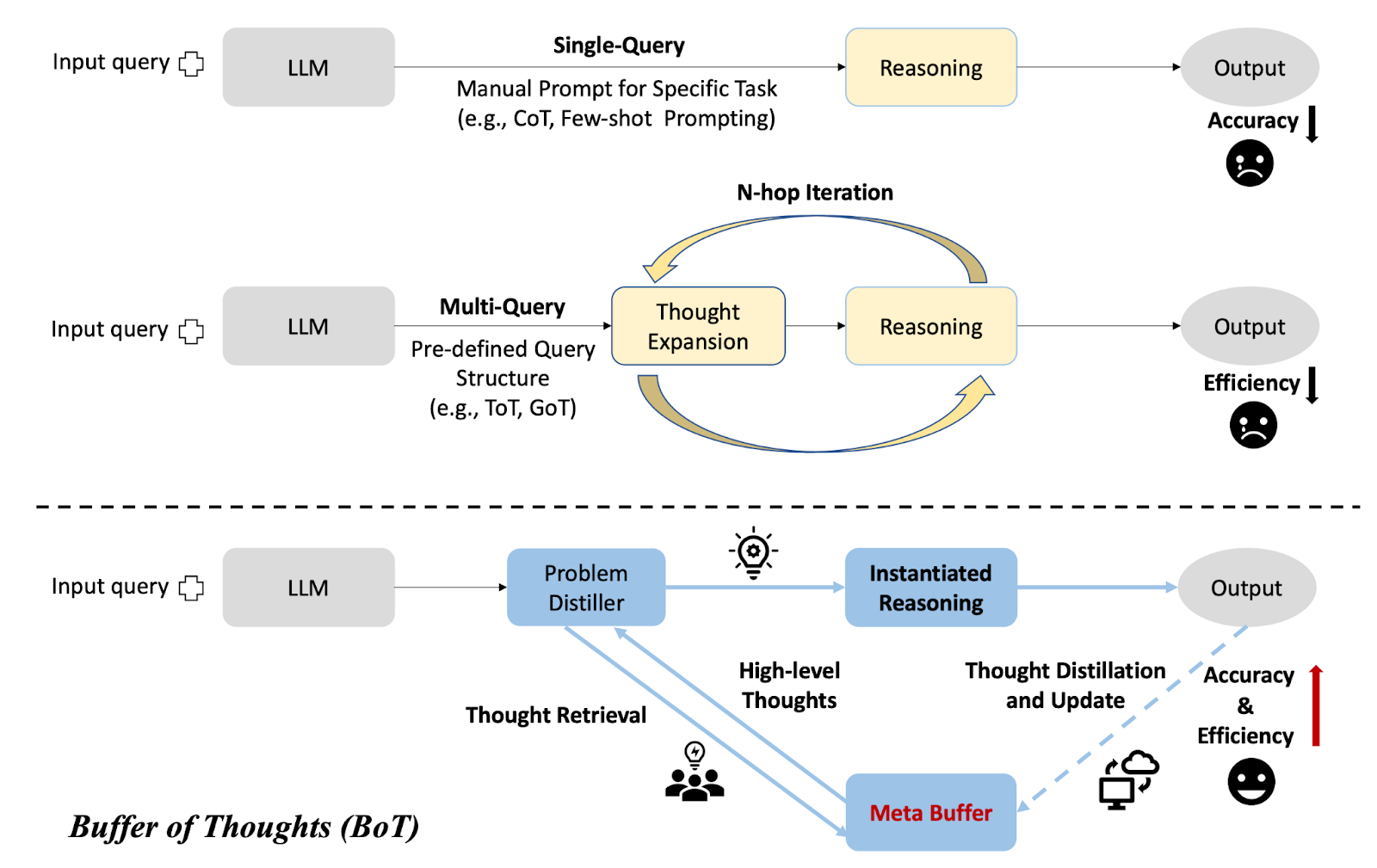
The BoT process has four main components:
The problem distiller extracts the essential parameters and variables from the problem, and outlines the objectives of the input task and any corresponding constraints.
The meta buffer is a buffer of problem-solving templates. There are six problem-specific templates for tasks — such as text comprehension, mathematical reasoning, or programming — and three general-purpose templates.
From the thought-retrieval process, the instantiated reasoning process selects the template that best matches the input query. This process uses both the template and the distilled information to generate a solution to the query.
Finally, the thought distillation and update process uses any new information gained from problems that have been solved using BoT to update the thought templates. This helps the BoT process apply successful problem solving techniques to new problems.
To better understand how BoT actually works, here’s an example from the paper that we’ve summarized for solving the following mathematical problem:
On average, a shop sells 20 shirts every day for a profit of 40 yuan each. The shop wants to expand sales, increase profits, and reduce inventory. An investigation found that for every 1 yuan that their shirts decreased in price, on average they’d sell 2 more shirts per day. How much should the price of each shirt be reduced to average a 1,200 yuan daily profit?

According to the results in the paper, the BoT process outperformed seven other problem solving techniques on 10 different tasks, such as multi-step arithmetic, sonnet writing, and checkmate-in-one (chess). BoT is also much more efficient than competing methods that use multiple queries, and is less affected by the inherent randomness of LLM outputs, achieving a higher problem-solving success rate than other methods.
The authors say that BoT often struggles on tasks that require human creativity since templates aren’t as helpful for these problems. They also found that it is quite sensitive to the quality of the underlying LLM. I also have some thoughts about the BoT process, so it’s ✨Speculation Time!✨ I suspect that BoT’s performance would be highly sensitive to the types of tasks it’s used to solve and the library of thought templates in its thought buffer. This isn’t a dig at the BoT method, since I think it’s reasonable to expect that the templates need to be curated and expanded to make the BoT a more general problem solver. I also suspect that human curation of these templates would be much more effective than automatic curation via the proposed thought-distillation approach, but that obviously isn’t very scalable.
Finally, I think we might be reaching the limit of how much we can improve an LLM’s problem-solving ability by augmenting its generation process with techniques such as CoT, ToT, and BoT. The BoT method is essentially a way to retrieve instructions for solving particular problems. But this isn’t really a general solution to using LLMs to solve problems, and ultimately, it isn’t a replacement for good LLMs and neural network innovation.