
LLMs can add hidden watermarks that survive human paraphrasing
Paper: On the Reliability of Watermarks for Large Language Models

Summary by Adrian Wilkins-Caruana
Back in March, I described a paper by Kirchenbauer et al. that introduced a new LLM watermarking method. A watermark is a signal in AI-generated text that’s unnoticeable to humans but easy for a simple algorithm to detect. If you’re anything like me, you’re probably thinking, “I can remove a watermark from an image in Photoshop, so I can probably remove one from text, too.” Well, today’s paper is a follow-up by the same group of researchers that wrote the previous watermarking paper. In their new paper, they look at how reliably algorithms can detect watermarks after the text has been paraphrased.

Before we jump into the paper, let’s do a quick refresher on how watermarking works. When generating the next token, the LLM is strongly biased to choose tokens from a very limited vocabulary, say 20% of its total vocabulary. The tokens in the limited vocabulary are called “whitelist” tokens, and the set of whitelist tokens change after each newly generated token (i.e., there isn't a fixed set of whitelist words; instead, each word, in context, is identified as whitelisted or not). Due to the LLM’s strong bias to choose whitelist tokens, they appear much more frequently than 20% of the time. And the more often they appear, the more likely it is that the text was generated by an LLM.
First off, the authors improved this watermarking method by making the watermark token subset more opaque to an outside observer. They did this because, with the previous version, an algorithm could analyze pairs of generated words to discover the watermarking scheme. So they explored different ways of determining the random whitelist subset and, after testing several variants, settled on a method they call Min-SelfHash. It uses the yet-to-be-generated token (the token with the greatest logit) and the three most recent tokens (for a total of 4 tokens) as a seed to determine the random whitelist tokens. They chose this method because it had the best compromise between degradation of the generated text quality (it’s as good as the original method in this regard) and being more robust (~96% ROC-AUC) to a paraphrasing attack than the original method (~92%).
So, how resilient is the Min-SelfHash watermarking method against a paraphrasing attack? The authors explored three types of paraphrasing techniques: when the watermarked text is paraphrased by a human, paraphrased by another LLM, and mixed into a larger, non-watermarked paragraph (the authors call this last technique “copy-paste” and abbreviate it CP). The image below shows these techniques, and the green dashes represent detected watermark tokens.
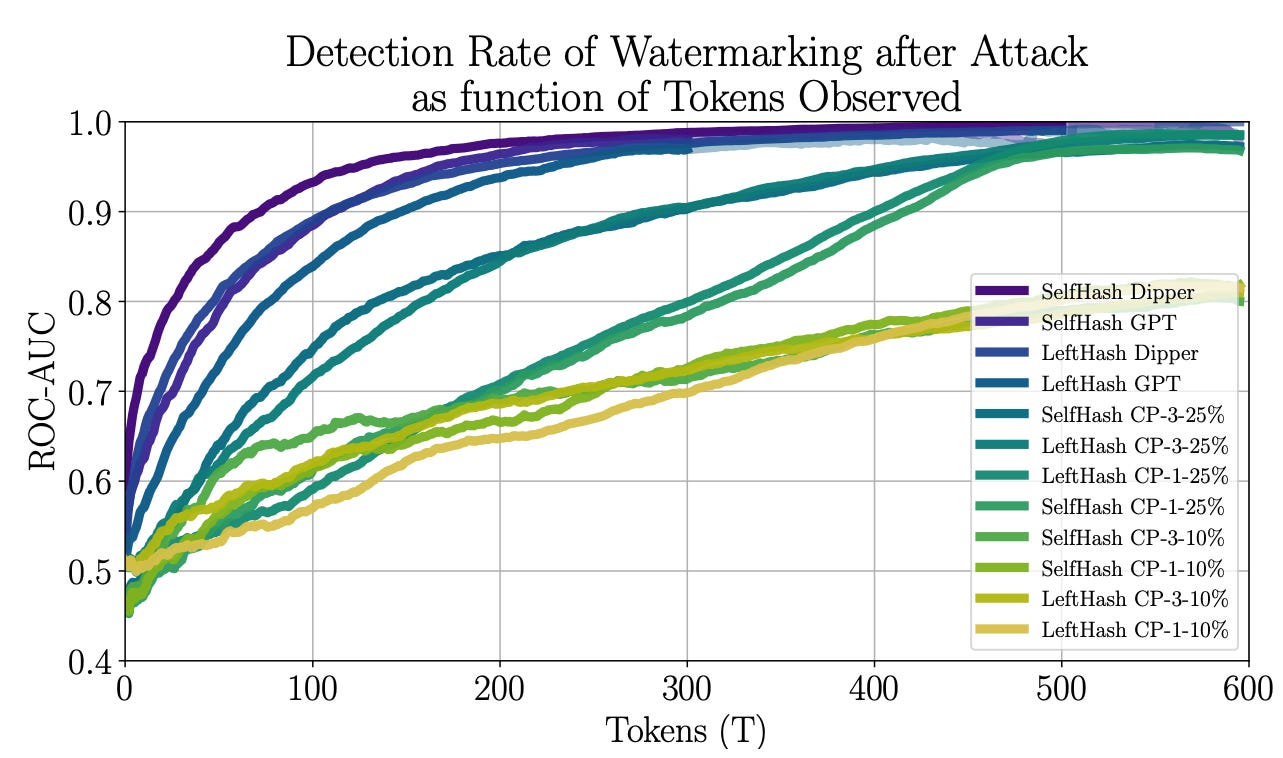
The first key observation from the paper is that the detection algorithm’s likelihood of detecting watermarked text increases substantially as it observes more tokens. While un-paraphrased text can be detected 90% of the time in as little as 10 tokens, watermarked text that’s been paraphrased by GPT-3 or Dipper (a paraphrasing LLM) can only be detected 80% of the time with ~100–150 tokens. A copy-paste attack is more robust but, after observing ~600 tokens, all methods can be detected ~80% or more of the time. The graph below shows these results, with the number of observed tokens on the x-axis and a metric of detection success on the y-axis.
Next, the authors look at the watermark’s efficacy when the text is paraphrased by humans. Compared to LLM-based paraphrasers, people were far more successful at diluting the watermark, reducing its efficacy. The figure below shows the watermark-detector’s confidence (y-axis) after observing T tokens (x-axis). The confidence is measured using a z-score: z=2 corresponds to moderate 97.8% confidence, while z scores above 4 correspond to “there’s no way this was written entirely by a human” confidence of at least 99.8868%, and so on. LLM paraphrasers were confidently detected after ~100 tokens at z=2, while ~200 tokens were needed to detect human paraphrasers with the same confidence. But even human paraphrasers couldn’t evade the detector: They were confidently detected after ~800 tokens (z=4), which is about 600 words.

When it comes to LLM-watermarking, this team’s original paper really opened my eyes to the fact that it’s possible to embed unnoticeable signals in text — LLM-generated or not. Now, this study tells me that not only is the signal invisible to people, but it’s also not really possible to remove it! For all we know, black-box LLMs like GPT-4 could already have invisible watermarks in their generated text. While this is pure speculation, it would be to OpenAI’s benefit to do something like that to, for example, detect GPT-4-generated text online and ensure it’s not reused for training. Or, the LLM could alternate between using one of two different whitelists to embed a binary signal into the text to say something like, oh, I don’t know, “S.O.S” 😶 (Gulp!) So, use LLMs with caution – you never know what they’re really trying to say!