
Can you tell if this text was written by a human?
I can.


You may be shocked to hear this, but I heard a rumor that some particularly rapscallious students have tried to pass off the work of ChatGPT as if they had written it themselves. (The impropriety!) Even more soul-shaking is the thought that perhaps one day an unscrupulous content creator may use ChatGPT to spew forth articles which are not entirely faithful to reality. What has the world come to, when misinformation is mass produced willy-nilly?
With all those scruples tossed to the wind, it would be nice to know, at a glance, if something was written by a human or by a machine.
That’s what today’s paper is all about. The key idea is that the creators of a language model can choose to subtly influence the vocabulary used by the large language model (LLM) in such a way that the meaning is the same, while the origin of the writing is clear — to an algorithm which can recognize the signature lexicon. It’s a new kind of steganography.
— Tyler & Team
Paper: A Watermark for Large Language Models
Summary by Adrian Wilkins-Caruana
Watermarking is a way for AI text generators to choose their words in a predictable way so computers can recognize that the text was AI-generated. When a watermark is really good, human readers don’t notice it but computers can detect it easily. Kirchenbauer et al. have created a watermarking framework that doesn’t sacrifice the generated text’s quality and can be efficiently detected.

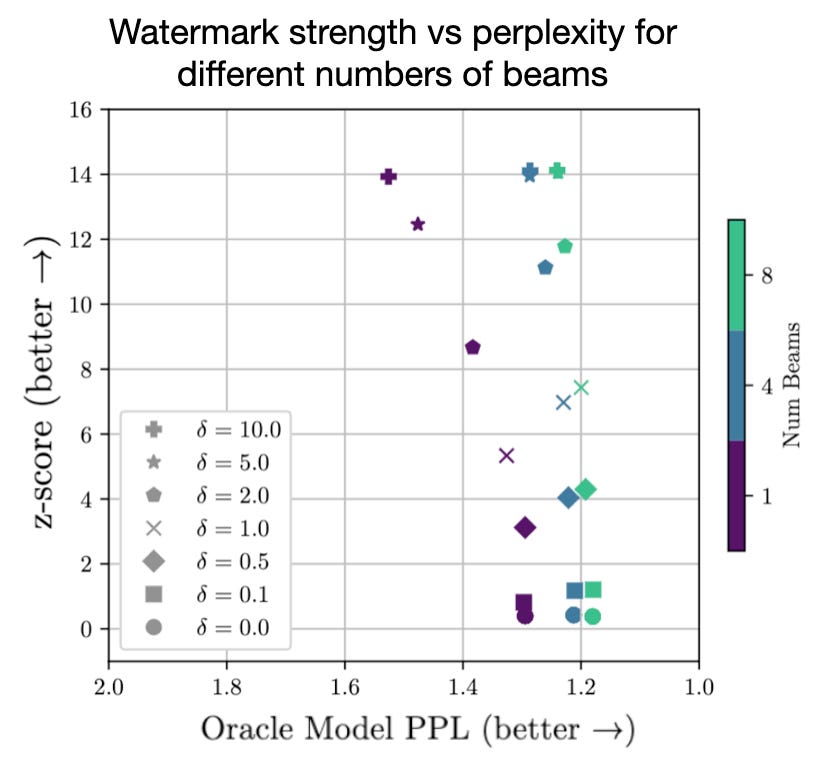
Their watermarking method strongly encourages the AI to use a very restricted vocabulary of tokens (called whitelist tokens) when generating new tokens. Even though humans don’t notice the high frequency of whitelist tokens in the generated text, an algorithm can easily detect them. Based on the frequency of these tokens, a statistical test determines the likelihood that the text was generated by vocabulary-restricted AI. The AI can occasionally use non-whitelisted tokens when it really makes sense (i.e., SpongeBob Square___). This doesn’t compromise the watermark’s efficacy, as long as the generated text isn’t too short (~25 tokens is sufficient for a robust watermark).

The watermarking is implemented by modifying the AI inference algorithm. First, the whitelist changes with each newly generated token and is seeded by the previous token. Next, when predicting the next token, the logits (i.e., likelihoods) of whitelist tokens are artificially increased by a small amount 𝛿, so the AI chooses whitelist tokens most of the time but can sometimes choose non-whitelist tokens. During generation, a beam search can help the AI generate better text under the watermarking constraint. This works by searching different generation paths and choosing ones that maximize both whitelist tokens and text quality.
PS This content has been brought to you today by the humans (not the LLMs, though we are still friends).