
A 47B LLM needing only 13B weights in memory
Paper: Mixtral of Experts

Summary by Adrian Wilkins-Caruana
As a general principle, when more parameters are added to a neural network, it becomes more capable but requires more time and computation. In recent weeks, we’ve discussed several papers (here and here) that try to make bigger, more capable neural networks run quicker by intelligently using only a tiny fraction of the network’s total parameters. Today’s paper also tries to be clever about which parameters to use, but its approach is unique: Instead of turning off individual neurons or disparate subsets of neurons in part of the network’s layers, a team of researchers at Mistral AI proposes to turn off many layers of neurons at once.

The proposed LLM is called Mixtral, which is a play on the research group’s name, as well as the word “mixture” in mixture of experts (MoE), a machine learning technique. An MoE uses multiple expert networks to divide a problem space into homogeneous groups. Unlike an ensemble, which combines the result from all networks, an MoE only uses two experts at a time at each step during inference. Mixtral has several MoE layers — which are groups of these experts — where a transformer model would typically have a feed-forward block. An MoE layer consists of eight feed-forward blocks and a router. The router selects which two experts will process the input; their results, which are just tensors, are then averaged together (with a weighted average, as we’ll see in a sec). This process is shown below. Aside from replacing the feed-forward blocks with MoE layers, Mixtral is otherwise an ordinary transformer.

The router is quite simple. It’s just a fully-connected layer with the same number of input neurons as the input size, and as many output neurons as the number of experts in the MoE layer, which in this case is 8. The router’s output is then normalized so that the sum of the output values is 1 (so you can think of it as a probability vector), and the experts that correspond to the top two values in the router’s output are the experts that will run for that token in that MoE layer. You can think of the output values of the router as how much it thinks each particular expert will be useful for that specific input. Before summing the outputs from the two selected experts, they are linearly scaled by this usefulness value from the router.
Unfortunately, the paper doesn’t describe how to train such a model. My guess is that all the experts are trained simultaneously, with the router selecting all experts all the time. This would mean that the performance benefits of an LLM that uses MoE are only realized during inference, and that training Mixtral 8x7B would be about as difficult as training an LLM with ~47B parameters (the full model has about this many weights). As a point of comparison, you could read Belcak and Wattenhofer’s paper Fast Feedforward Networks, which explains in detail how they train a network that only uses a subset of its weights at inference time (I suggest starting with the paragraph on page 2 that begins, “The process enabling the fragmentation…”).
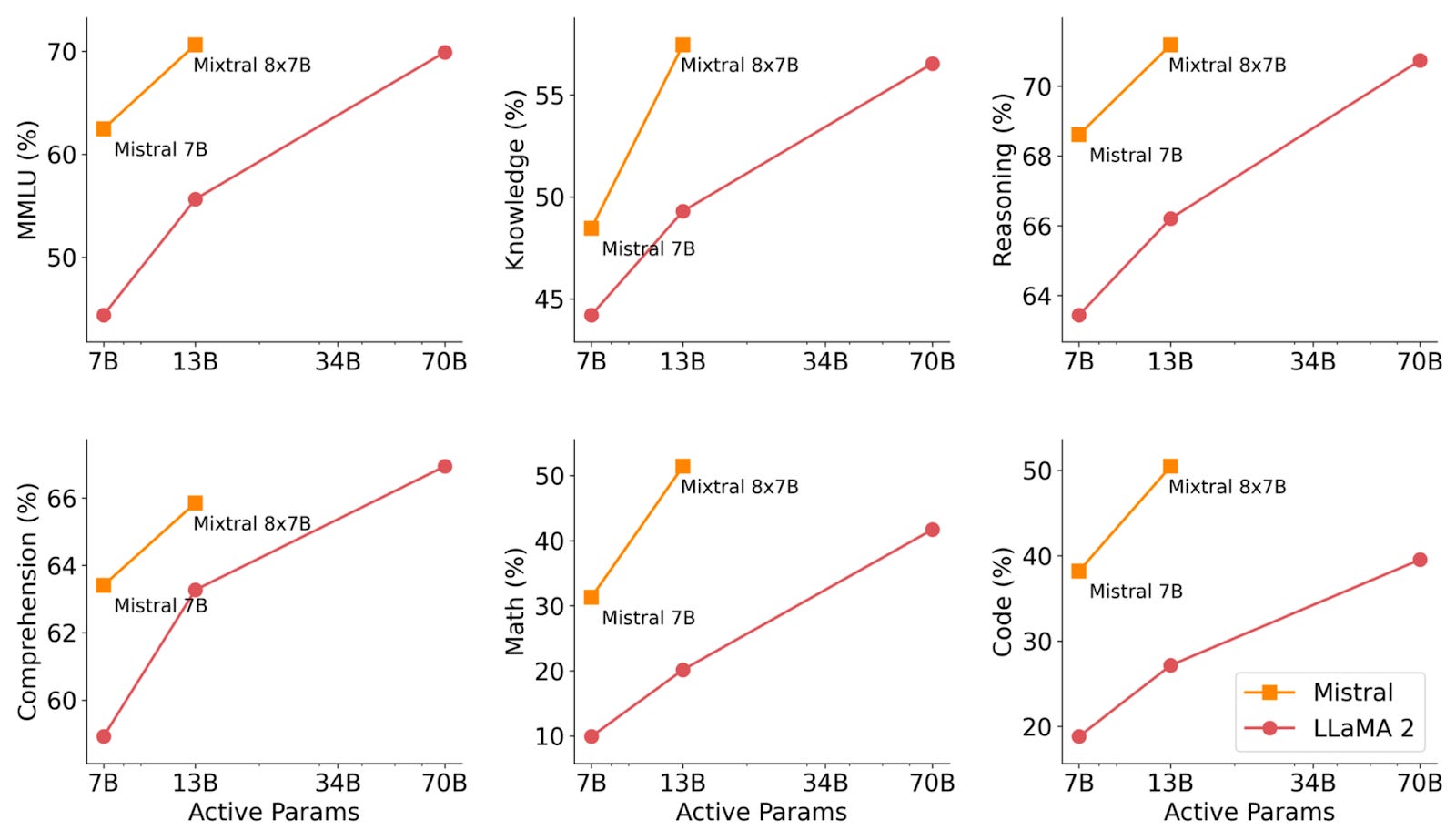
The Mistral AI researchers evaluated their model, Mixtral 8x7B, on many different datasets and language tasks. They compared it with Mistral 7B, which is a Mixtral model that has regular feedforward layers instead of MoE layers, as well as against LLaMA 2 models of various sizes (7B, 13B, and 70B). In the figure below, active parameters refers to the number of parameters used during inference. For the Mixtral model, this is approximately 2 times 7B (since each MoE layer only uses two experts). For all the other models, it’s just the number of parameters.
We can see two very clear trends across each of these tasks:
Mistral 7B, the non-MoE LLM, is already quite a bit better than the same-sized version of LLaMA 2, and:
Aside from the comprehension task, Mixtral 8x7B either matches or outperforms LLaMA 2 70B on every task!
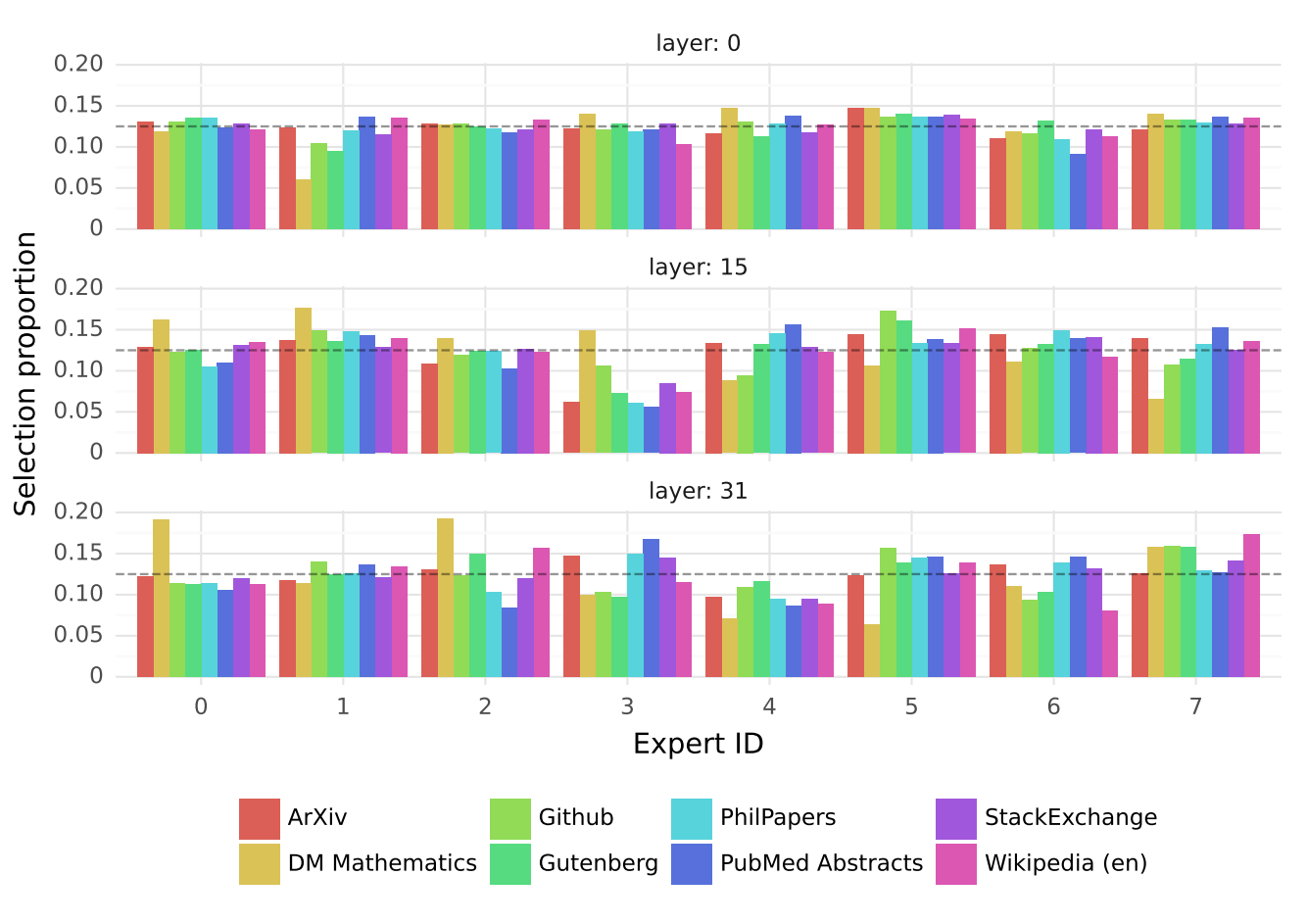
Now, you might be thinking, “These experts — what are they experts in?” Good question — the Mistral AI researchers wondered that, too. They analyzed which experts were selected in different kinds of text and at various depths in the LLM, i.e., the first, middle, and last MoE layers, which are layers 0, 15, and 31 respectively. The initial layer seems to be more evenly distributed (used equally on all tokens) than the middle and final layers. You might expect the first layer to be more evenly used since deeper layers tend to be more specialized. Surprisingly, though, there doesn’t seem to be any obvious correlation between which expert is selected and what kind of text the model is processing. The only exception — and it’s a bit of a stretch — is that mathematical text seems to slightly favor some of the experts in the middle and final layer (notice the taller/shorter yellow bars in layers 15 and 31 below). But the researchers think this could be explained by the dataset’s synthetic nature and its limited coverage of the natural language spectrum.
Looking more closely, though, the researchers think that the router’s expert-selections seem to be more correlated with syntax than with topic. You can see this in the figure below, where the color of the highlighted token indicates the top-selected expert in the specific layer. (The top example is actually Python code for how to program an MoE layer! It’s surprisingly simple, right?)

When I first read this paper, it reminded me of our brains’ specialized regions for particular tasks: one part for processing information from our eyes, another for processing information from our ears, and so on. This made me think, “Aha! So we can make LLMs more efficient by making them more like our brains.” However, the analysis above, which concludes that the experts focus more on syntax than subject, seems to contradict this idea. The paper omits training notes for Mixtral 8x7B, but I wonder what a sophisticated training approach could achieve if it were to selectively use particular experts chosen based on the semantics of the input, rather than based on the syntax. Maybe it’ll be worse, maybe it’ll be better. What do you think?