
Fast LLMs, even when they don't fit in RAM
Paper: LLM in a flash: Efficient Large Language Model Inference with Limited Memory

Summary by Adrian Wilkins-Caruana and Tyler Neylon
To quickly run an LLM, it’s best to store its parameters in standard (non-persistent) memory — meaning in DRAM. But some LLMs have many billions of parameters, which is more than typical consumer computers can store in DRAM. For example, a modern MacBook Pro can only store up to about 20B parameters in 10GB of memory. The best open-source LLMs contain >70B parameters, but many other models contain hundreds of billions.

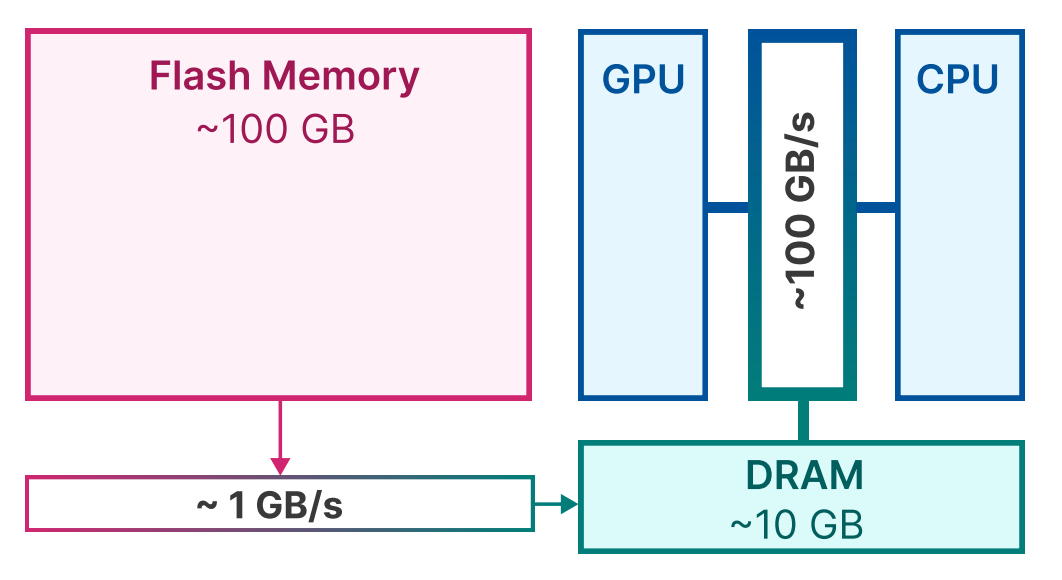
To circumvent DRAM capacity limitations, computers can store and retrieve information from slower but higher-capacity long-term memory, called NAND or Flash (NAND memory is named after the NAND — or “not-and” — logic gate). The figure below shows the layout of a typical computer’s memory architecture. While the processors have fast access to DRAM, their access to Flash memory is much slower. This presents a tradeoff between speed and capacity. Computers can run LLM models that exceed their DRAM capacity by constantly swapping in and out subsets of the model’s parameters, but they’ll be dramatically slower. Today’s paper suggests a way to have the best of both worlds: big LLMs and fast inference.
To understand what’s possible, let’s see just how much the authors’ methods improved inference speed when a model’s parameters were stored in slow Flash memory. The figure below shows speeds for two inference implementations: naive, which naively loads each parameter from Flash when it’s needed; and ours, which is the authors’ implementation. In the naive case, most of the inference time goes into loading parameters from Flash. This loading time would be much closer to zero if the parameters were all stored in DRAM. Some additional time, in blue, is taken by number-crunching (compute). The authors improved the compute speed a bit, but they mostly improved the parameter-access latency.

Neuron activations in a neural network are just values that depend on the model’s parameters and input. An activation can, in theory, be either a positive or negative value, but often negative values are ignored (or zeroed out) to help the network focus on stronger activations. In practice, this means that over 90% of a network’s activations will end up computing to zero, which results in a lot of unnecessary computation. But we don’t know before computation which activations will be zero, since it depends on the model’s input. However, the authors used something called a low rank predictor, which is a way to predict which neurons will have strong activations. They used this predictor to determine which small subset of model parameters should be loaded. This change improved inference speed by 48%, and additionally reduced the amount of computation required. You might think that this would affect the quality of the model’s result, but actually the authors measured no significant loss in model quality across three zero-shot prediction tasks.
If you’d like to read more about how the sparsity of LLM neurons can be exploited, consider our recent summary of UltraFastLLMs.
But that’s not the only optimization they found! Parameters that are useful for one token will likely be useful for the next token, too. Based on this idea, the authors cached parameters that were predicted to be useful into DRAM, so that they didn’t need to be loaded again if they were also predicted to be useful for the next token. The parameters were then released from DRAM after a few more tokens were predicted. The authors call this approach windowed caching, and it’s shown in the figure below. This technique significantly reduced the time spent loading parameters from Flash to DRAM, improving inference speed by 450% beyond what was gained by using the above predictor.

Their next clever optimization was to rearrange how the LLM’s parameters were stored in memory. Once the above-mentioned predictor determined that a particular neuron was necessary, the model then had to load two specific parameter sequences that aren’t normally contiguous in memory. These are a single row and a single column of the two matrices that dictate the network’s behavior associated with that neuron. Even though these two parameter sequences live in different matrices, they can be stored as a single sequence in memory instead of in two separate locations. In general, it’s more efficient to load one large chunk of memory than two half-chunks because each load operation has additional overhead. This change improved inference speed by a further 89%.
Overall, the authors report that this method improved inference throughput by 4–5x on CPU, and by 20–25x on GPU. These are impressive results, and they definitely open up the possibility of more sophisticated neural networks running on ever simpler devices, like smartphones, smartwatches, or — and I may be letting my imagination get the better of me here — a smart fridge that can talk and help me decide what to cook for dinner. Ah, to dream the impossible dream.