
We don't know why GPT works so well.
OpenAI researchers are learning more.

AI progress in the past year has been staggering. One of the weird (and for some folks, frightening) aspects of this progress has been that we don’t know why things are working so well.
Let’s back up for a minute. Waaay back in 2017, a Google team published the paper Attention is All You Need, which introduced the pivotal transformer mechanism. This device is part of a neural network, similar to the way an AND gate is part of a circuit (a transformer is more complex than an AND gate).
The transformer mechanism works well. So well that it’s revolutionized what’s possible. Attention mechanisms (similar to the transformer) are a key ingredient in stable diffusion models as well (today’s popular image generators). But their evolution has been more akin to discovering a drug in the wild than to constructing a well-understood device. For example, today’s paper asks the simple question:
Can we understand the job performed by an individual neuron in a GPT model?
A partial answer has begun to take shape, but the deeper truth is still ahead.
— Tyler & Team
Paper: Language models can explain neurons in language models
Summary by Adrian Wilkins-Caruana
Imagine trying to decipher the thoughts of everyone in a bustling city by looking at its skyline — sounds challenging, right? That's the level of complexity that researchers face when trying to understand how language models work. We can observe the results, but figuring out the underlying process? That's tough.
So how do we peek inside these models? Traditional methods involve people manually inspecting model neurons, but this isn't scalable for big models, which sometimes have billions of parameters. Enter a new automated method: OpenAI is using GPT-4 to generate and score explanations for the behavior of these neurons.
To get an idea of how this works, imagine trying to understand a neuron in GPT-2. This shouldn’t be too difficult, since you’re really smart and a GPT-2 neuron just outputs a simple number that says “I’m excited!” or “This is boring” when it sees some text. Let’s give it a crack.
In the GPT-2-generated text below, the highlighted text indicates that the neuron in question is excited:
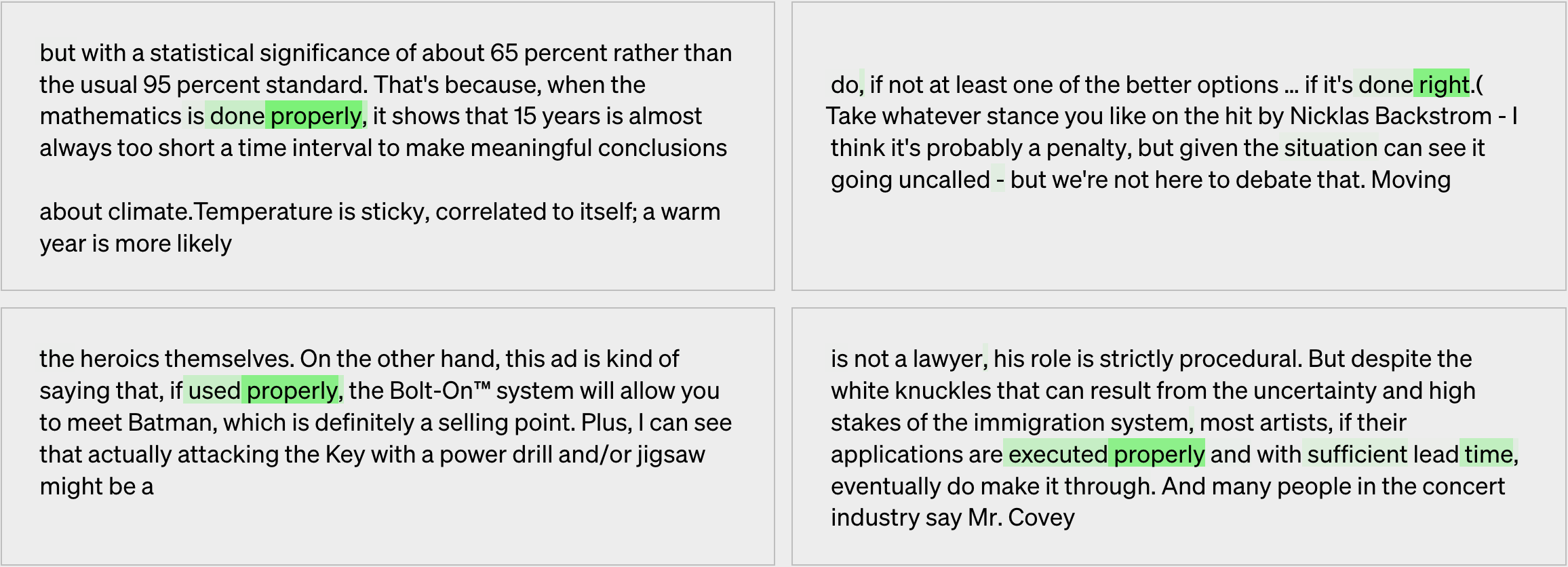
Based on these examples, we might first conclude that this neuron gets excited about the concept of things being done correctly. Upon closer inspection, we can see in the lower-right example that it also gets a bit excited about “sufficient lead time,” so maybe we can generalize by saying that the neuron gets excited about things occurring under ideal circumstances, which is a bit more abstract. What we just did required abstract thinking and reasoning (smart-human high five! 🙏). We can now quite easily score how well we understand this neuron by trying to “simulate” the neuron’s excitement: To do this, we try to guess which words in some new GPT-2–generated text the neuron would be excited about. The score of how well we understand the neuron is computed by comparing our guesses to the neuron’s actual excitement level.
So, back to using AI to explain AI: OpenAI is trying to explain the neurons in GPT-2, an LLM, using GPT-4, another LLM. The setup is basically identical to our human example, except instead of prompting a person to explain and simulate GPT-2, we prompt GPT-4 to do so. Here’s a comparison of GPT-4’s excitement-guesses based on its understanding “words and phrases related to performing actions correctly or properly,” and the GPT-2 neuron’s actual excitement level. The left example is basically spot-on, but it gets it a bit wrong on the right.

With this setup, OpenAI found that neurons in bigger, more complicated models are harder to explain. Actually, most of GPT-2’s 300,000 neurons are not easy to understand using this method, with an average understanding score of about 9% for GPT-2’s neurons. But about 1,000 of the neurons were well-understood, with scores of 80% or higher — that’s pretty good!

The researchers also noticed that explanations for neurons that activate for a particular token get more abstract the deeper in the network the neuron is. For example, explanations for “Kat” are finally recognized as my favorite chocolate bar in layer 25:

It’s hard to say exactly why most of the explanations are so poor, but one reason could be that GPT-4 needs to see many different kinds of examples where a neuron gets excited: ones that show all the diverse ways that the particular neuron gets excited, not just the same kind of example over and over again. While these results aren’t groundbreaking, OpenAI hopes to drive developments in our understanding of AI models by releasing their code and GPT-2 neuron explanations to the public.
I’ll leave you with an image of Marvel-neuron — a neuron that’s just crazy about the Marvel universe.
