
Vision transformers can see in stereo
[Paper: Grounding Image Matching in 3D with MASt3R]

Summary by Adrian Wilkins-Caruana
Your brain is amazing. Whenever you open your eyes and look around, you experience your surroundings in 3d despite only having two 2d views of it, one from each eye. This 3d environment that you perceive is so good that, without much effort at all, you can accurately judge things like how hard and in what direction you need to throw a ball so that it gets to a specific person, or how far it is between your car and a red traffic light in the distance.

To give you an idea of why it’s amazing that your brain can do this, let’s quickly break down the process of multi-view stereo (MVS) reconstruction, which is computer-speak for “How do I turn the two flat images from these two cameras into a 3d model of what they saw?” First, a computer needs to identify and match the same parts of the images. Then, using information about where each image was taken and other details like the parameters of the camera’s lens, along with some complicated mathematics, it can reconstruct where in 3d-space each of those parts of the image must have been. Believe it or not, that’s actually an oversimplification. The figure below, taken from the paper of a popular MVS technique called COLMAP, shows a breakdown of an actual MVS pipeline.
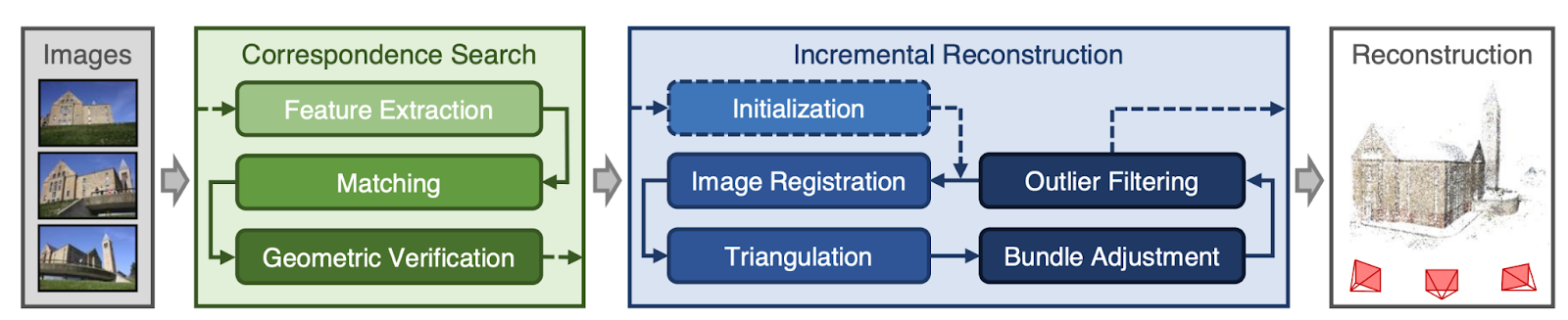
The approach taken by COLMAP and other MVS techniques — that is, using mathematics and algorithms — seems perfectly sensible to me, and it works quite well. But is this what our brains are doing when they see the world? Maybe. Or maybe our brains operate more like a new machine learning-based approach called DUSt3R.
Like COLMAP, DUSt3R turns images into a 3d point cloud, but in a completely different way. Here’s how it works: First, the model extracts small patches from two images, and then separately encodes them using the same Vision Transformer (ViT) encoder. Then, two ViT decoders share information about these patches via cross-attention to generate one feature vector for each patch in each image. Finally, a “head” (a fully-connected layer) predicts the 3d positions {x, y, z} of each pixel in each image, as well as a confidence value that indicates how confident the network is about each pixel’s prediction. Importantly, the 3d positions predicted by the head for the second image are in the same coordinate space as the one from the first image.
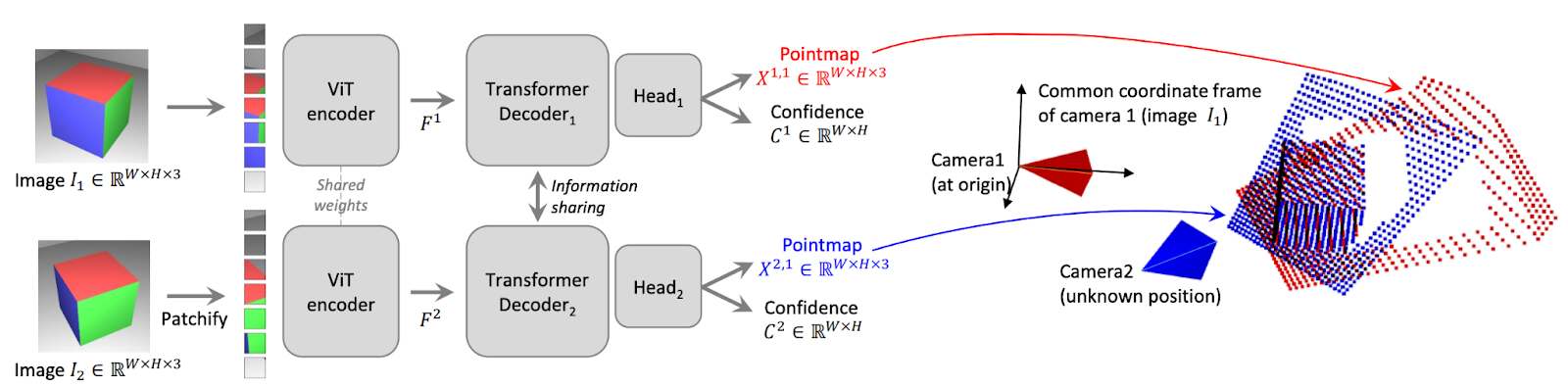
The authors used supervised learning to train their model, which means they needed the corresponding 3d locations of pixels in image pairs of the same scene. Their training dataset consisted of about 8 million examples of this kind of data, and contained both indoor and outdoor images, as well as images of objects. Then, to optimize the model’s parameters, they used a regression loss, which is just the average error, or distance, of where DUSt3R thinks the pixels are versus where they actually were. These errors were each scaled by the confidence value that DUSt3R predicts, which is helpful because sometimes it’s really hard to know the exact location of particular pixels, like ones in the sky or in reflections.
Compared to about a dozen other MVS methods (some neural network-based, others more traditional), DUSt3R performed the best in terms of absolute relative error. But the more impressive result is DUSt3R’s zero-shot prediction accuracy (its accuracy on datasets it wasn’t trained on), where it was almost as good or sometimes even better than non-zero-shot neural approaches. Note that the traditional approaches should also be considered zero-shot, since they weren’t designed for any specific dataset — but DUSt3R still seems to outperform these approaches more often than not. And remember: DUSt3R doesn’t need information about the cameras’ poses or their intrinsic parameters either!
The DUSt3R researchers recently followed up their method with an extension they call MASt3R. MASt3R improves on DUSt3R’s approach by emphasizing pixel matching: matching each pixel in one input image with the pixel of the same point (in the 3d scene) in the other input image. Here’s an example of pixel matching between two input images:

The figure below shows MASt3R’s architecture, which adds an additional head onto the ViT’s decoder. From the image patches, this head generates a vector of features for each pixel in each image; this new vector-per-pixel data provides the additional info MASt3R uses to match pixels across the input images. And MASt3R’s loss function is the same as DUSt3R’s confidence-weighted regression loss, but with an additional loss term that penalizes the model for every pixel that it incorrectly matches.
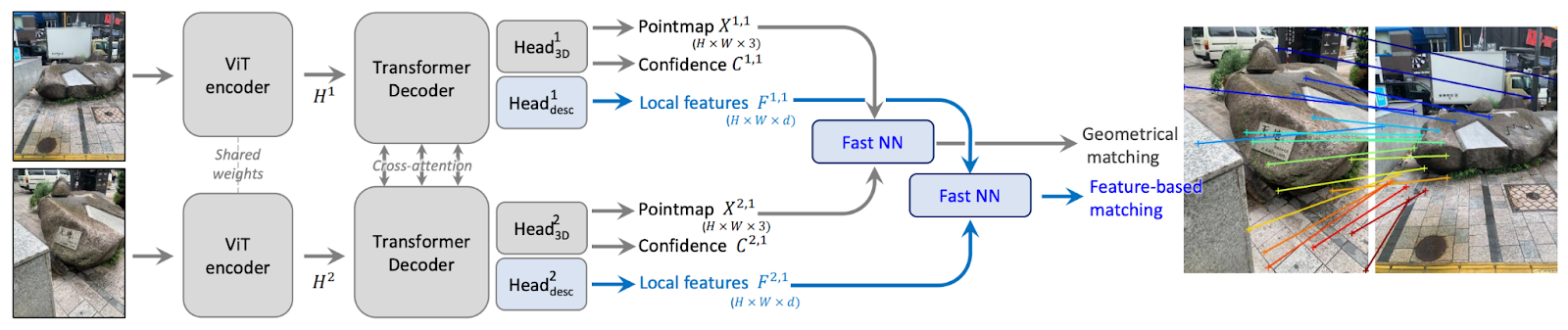
Without going too deep into the details of MASt3R, this extension (pixelwise matching) adds a lot of additional complexity (efficient pixel-matching is non-obvious), but the authors introduce clever algorithms for solving this and other related problems. All this effort is worth it, though, since MASt3R is both more accurate and more robust to viewpoint and illumination changes than DUSt3R. Also, aside from the main purpose of predicting point clouds, these models’ results can be used for things like camera calibration, inferring the cameras’ pose, depth estimation, and dense 3d reconstruction.
Being neural network-based, DUSt3R and MASt3R share afflictions similar to neural networks in other domains. Despite their impressive zero-shot performance, these approaches might need to be retrained to work effectively in contexts that differ substantially from their training data, such as in underwater or aerial imagery, or imagery with very wide or very long lenses. Traditional MVS approaches would be more robust to these sorts of changes, provided their models can be adjusted for these settings.
In either case, there’s no one-model-fits-all approach to MVS, much like how our brains are particularly well adapted to MVS from our two eyes, but would need to be “retrained” if our vision was suddenly inverted or if the shape and composition of our eyes suddenly changed in some way.This paper hasn’t brought us any closer to understanding how our brains do MVS, but it has shown that there’s more than one process that can achieve it. Maybe our brains work like DUSt3R, or maybe they have their own method that’s still a mystery.