
The visible transformer
Visualizing an LLM's inner thoughts

Several weeks ago, your humble AI newsletter covered an effort by OpenAI’s own researchers to understand the meaning of individual neurons in GPT-2. Their creative technique opened a window into GPT’s thoughts in the form of text descriptions, such as “Marvel characters,” to describe what a neuron specialized in (a “neuron” here means the output of a particular activation function in the neural network).
This week, we’re covering a clever set of ideas that gives us — instead of text descriptions — beautiful visualizations of the attention mechanism at work. As a reminder, attention (and its closely-related neural network device, the transformer) is the secret ingredient behind the ongoing AI revolution. Indeed, GPT itself stands for Generative Pre-trained Transformer. The intuition behind attention is the ability of a neural network to use a kind of key-value datastore that allows it to look up anything it has already received as input (or “thought about” in another internal layer), even if that input or thought is in the past, or arose in a relatively distant part of the network. A simple metaphor is the way a phrase on one page might refer to an idea from a previous page in a book.

This issue covers the cool ideas that give us new visibility into AI’s secret sauce. With a little more visualization insight, we might one day find that transformers are exactly what meets the eye.
— Tyler & Team
Paper: AttentionViz: A Global View of Transformer Attention
Summary by Adrian Wilkins-Caruana
People sometimes refer to neural networks as “black boxes,” since it’s hard to know exactly how they understand complex sentences or spot a dog among thousands of objects in an image. Wouldn’t it be nice if we could see inside these black boxes? Well, now we can! AttentionViz is a new way to visualize what goes on inside the attention mechanism of transformer neural networks, which are commonly used to model language and images. In my opinion, the most intriguing thing about AttentionViz is that it’s remarkably simple: It uses off-the-shelf visualization tools, but the Harvard researchers who created it used two neat mathematical tricks to unlock the tools’ potential.
As the name suggests, AttentionViz shows what’s going on inside a transformer by visualizing what’s happening inside its many attention heads. Here’s a refresher on how transformers work: The attention mechanism is how a transformer can learn relationships between all pairs of tokens in a sequence (like a sequence of words), and determines which pairs should interact. For example, in the sentence “The train is late,” one might expect a stronger relationship between the words “train” and “late” than between “the” and “is.” It does this via communication: First, the transformer’s weights generate queries and keys for each word, which are both just vectors of numbers. I like to think of queries and keys as buyers and sellers in a market: When the buyers want to buy the things that the sellers are selling, then they have a relationship.
So how can AttentionViz show us what’s going on between the queries and keys for the sentence “The sky is blue”? First, we find the query and key vectors for each word using the transformer’s query weights and key weights. Because these vectors typically contain hundreds of numbers, they can be difficult to visualize, so we use one of several dimensionality-reduction techniques to reduce them to two or three numbers. Then we visualize all of the points using a simple 2d or 3d scatter plot. If the query and key for two words are close together in the scatter plot (like “sky” and “blue”), it means the buyers and sellers are a good match for each other. The diagram below shows this process, and it’s a pretty faithful, simplified representation of how AttentionViz works.
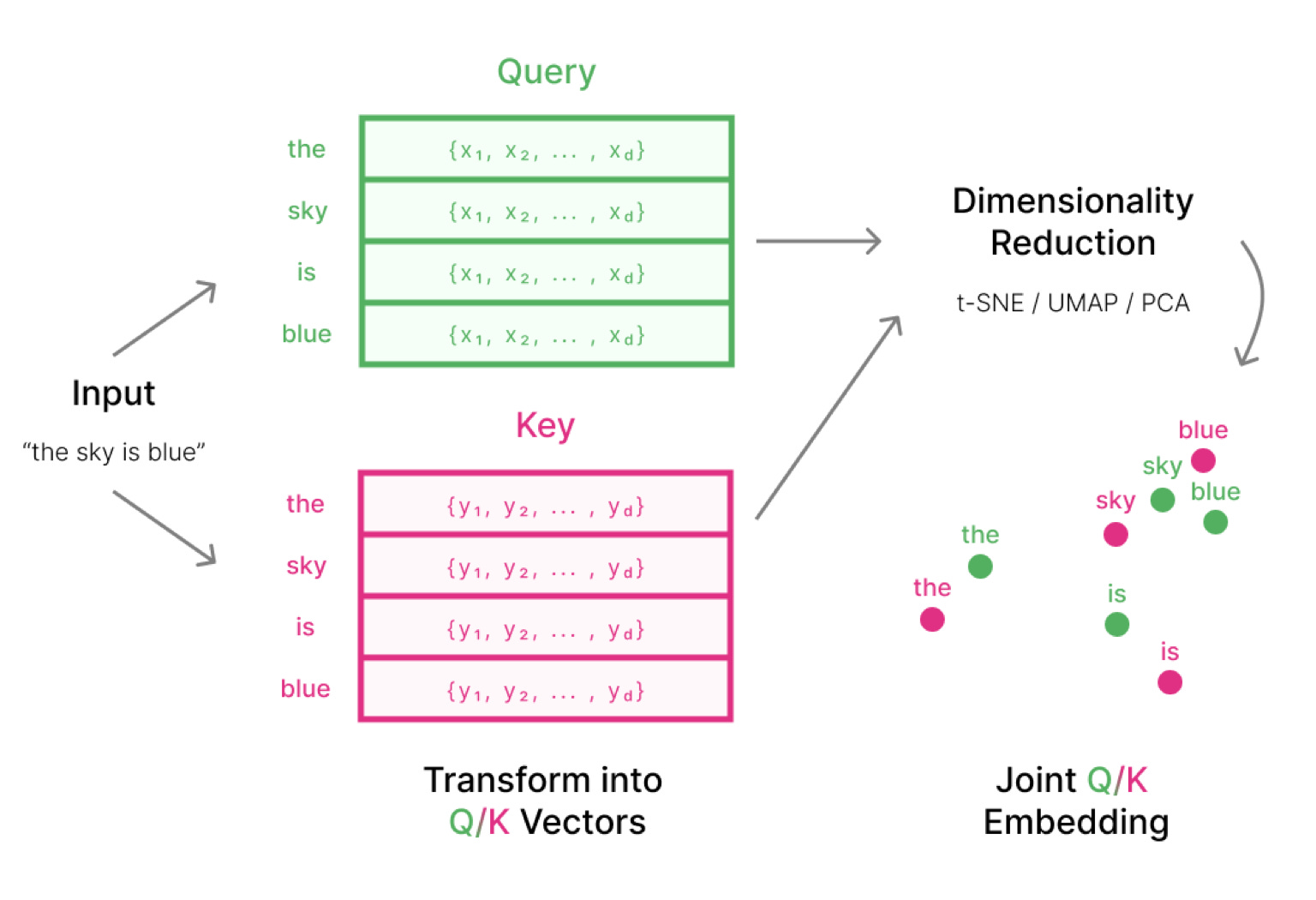
If this is all AttentionViz does, why has nobody tried this before? Well, I’m sure many people have! The thing is, the buyers and sellers in the dimension-reduced vectors probably didn’t pair up as nicely as we saw above. Instead, people who’ve tried to do this might have seen something like this:

In this dimension-reduced scatter plot, the distribution of the queries and of the keys look like they have the same structure, but something looks off: the queries and keys are offset from each other. This doesn’t mean that there aren’t buyer/seller matches — there are. Instead, what’s going on here is that the attention mechanism wasn’t designed for visualization, which means that just because some queries and keys have similar vectors, it doesn’t necessarily mean they’ll be near each other in the scatter plot. What we’d like to do is shift the keys (or the queries) so that the queries and keys are better aligned.
This is where the Harvard researchers noticed they could do something quite clever. They discovered they could shift the numbers in the key vectors without changing the attention weights. To understand the mathematical insight that lead to this, consider the following scenario:
Jack is 5 miles north of Jill.
Jack and Jill both walk 1 mile south.
Jack is still 5 miles north of Jill.
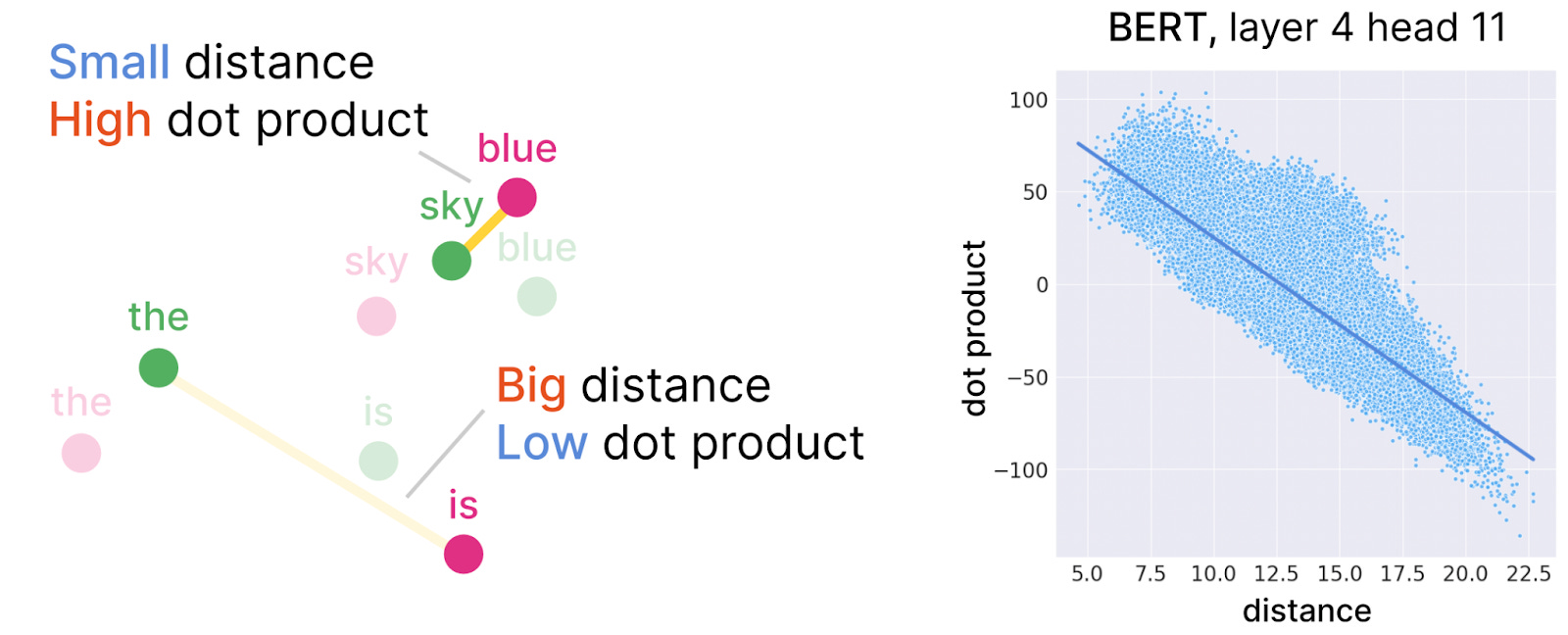
The distance between Jack and Jill stays the same as long as we move them both the same way. Similarly, when we calculate the attention weights of one query vector with all other key vectors, we can translate all the keys in the same direction and by the same distance without changing the resulting attention weights of the query vector to each of the keys! The researchers call this trick key translation, and it’s what makes the queries and keys more aligned in the AttentionViz scatter plot. (If you’re familiar with the softmax method, you can think of it this way: It's safe to translate all the key vectors by the same amount because doing so doesn't change the output of the softmax. Another way to say this is that softmax is translation-invariant.) After translating the key vectors, the resulting dimension-reduced scatter plot could look something like this:

But wait, there’s more! The researchers noticed they could use another mathematical trick. Sometimes, the queries might be a tiny cluster, but the keys might be a big, sparse cloud. In those cases, the researchers scale the queries by some factor (let’s call it c) and then scale the keys by the reciprocal of that factor (1/c). Just as with translating the keys, this process doesn’t affect the attention weights, but it improves the alignment of the queries and keys.
What does all this mathematical trickery yield? It generates a scatter plot where the distances between queries and keys is highly correlated with the dot product, which is the mathematical operation performed on the queries and the keys that determines attention weights. It’s not a perfect correlation, because the dimensionality reduction messes with things a little bit, but it’s pretty good because the relative distances in the 2d visualization tend to be quite close to the actual distances in the original, higher dimensions.
AttentionViz is also a web app where you can view these visualizations. There are several “views,” shown below, that let you interrogate the attention weights in several ways. In Matrix View (top), scatter plots for many different heads are displayed in a grid, showing their different structure. Single View (lower left) visualizes a single attention head’s weights. And Sentence View (lower right) overlays the words in a sentence and the attention weights between them, showing their relationship.

Often, when training a neural network, things don’t work the way you’d expect, even if your code doesn’t have any compilation or syntax errors. In these cases, it can be daunting to try and figure out exactly what’s going wrong, especially because the “code” of a neural network is just millions of numbers interacting with each other, not human-readable keywords and variable names. But AttentionViz can help us understand what’s happening in the network regardless of whether it works. Tools like AttentionViz are essential for developing AI, just like a debugger is essential for software development.