
The subgoals of attention units in LLMs
[Paper: Attention Heads of Large Language Models: A Survey]

Summary by Oreolorun Olu-Ipinlaye
Large language models have shown their utility across all kinds of tasks and they’re only getting better. Improving their performance often involves increasing their parameters rather than changing their architecture or reasoning pathways because LLMs are seen as black boxes, which makes it difficult to identify areas to adjust. But researchers have begun analyzing how LLMs think, focusing on their attention heads, a critical portion of the transformer architecture that LLMs are built on. The authors of today’s paper looked closely at LLMs’ reasoning processes by reviewing prior research on attention head interpretability.

To demonstrate how attention heads work, the researchers compared them to the way human brains solve problems. According to neuroscience, the brain’s problem-solving process involves four phases:
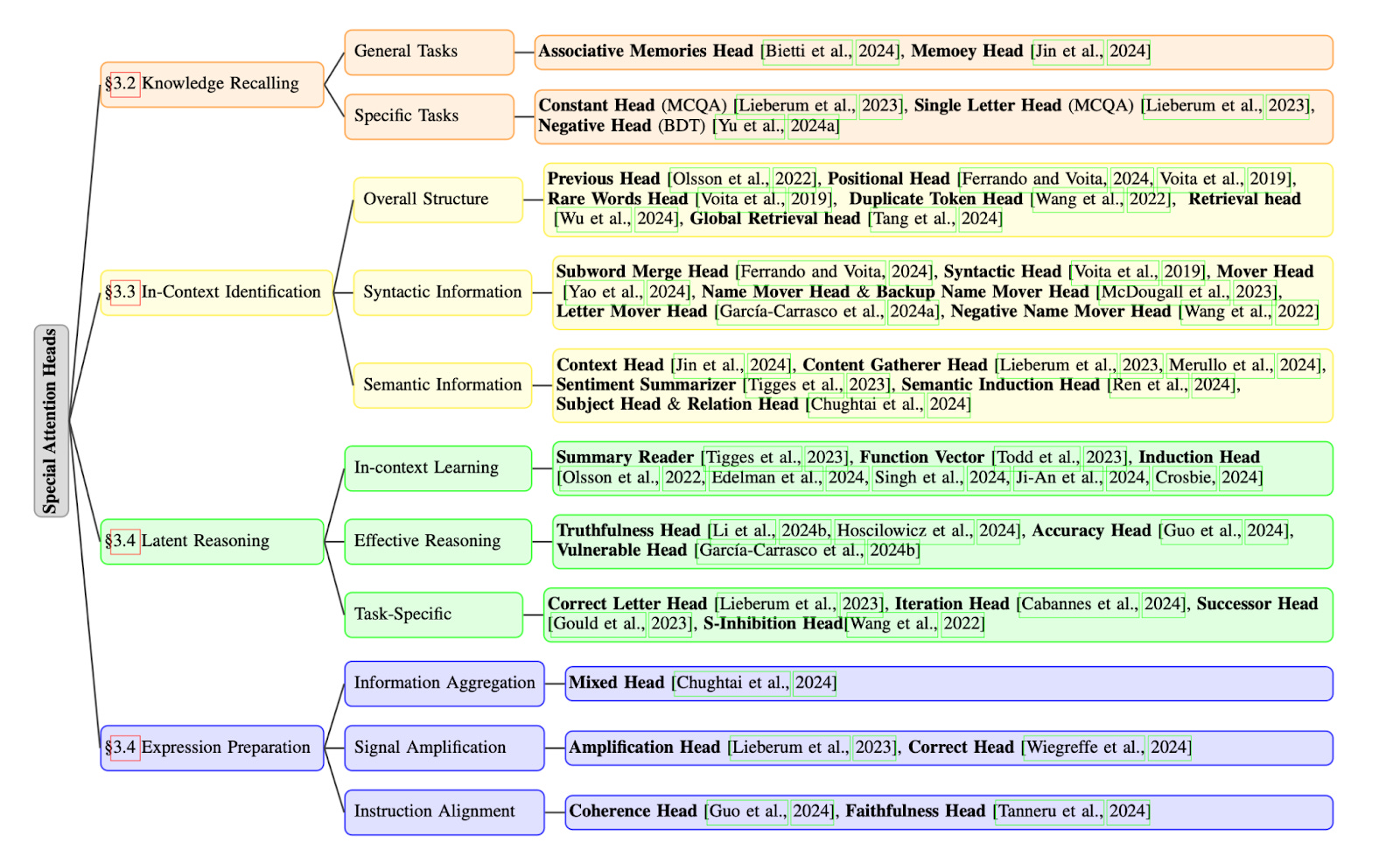
Knowledge Recalling: We recall relevant knowledge.
In-Context Identification: We analyze the context of the problem.
Latent Reasoning: We use that information to reason and come to a conclusion.
Expression Preparation: We express the solution in natural language.
The authors then draw parallels between this process and attention heads, which serve a comparable problem-solving function in LLMs. In the case of Knowledge Recalling (KR), LLMs learn during the training or fine-tuning process and this knowledge is stored in the model’s parameters — this is called parametric knowledge. The attention heads involved in this phase recall knowledge by initially guessing or focusing on specific context to retrieve relevant parametric knowledge.
Once the LMM has retrieved that knowledge, then comes In-Context Identification (ICI). The authors quoted past research that states that there are specific attention heads involved in identifying key information in a query. These heads focus on three elements of the query:
Structural information: overall context, positional relationships, rare words, and repeated content
Syntactic information: sentence components like subjects, predicates, and objects
Semantic information: task-relevant content, answer-related tokens, sentiment, and relationships between words
The next phase, Latent Reasoning (LR), is where the authors say specific heads of the LLM combine information derived from the KR and ICI phases and perform reasoning. During this stage, the model begins to "think" through the data, combining patterns, relationships, and insights from earlier phases to draw conclusions. Finally, the last phase, Expression Preparation (EP), is where certain attention heads take reasoning results and turn them into natural language outputs that the user sees. EP heads aggregate information from the ICI and LR stages, amplify signals of correct choices, and ensure that the output is coherent and clear. The image below provides an overview of all four phases and the specific attention heads involved in each one.
How exactly did the authors identify the functions of these attention heads? They used experimental methods that are categorized into modeling-free and modeling-required methods. Modeling-free methods modify the LLM’s internal representations while analyzing the impact on output. Modeling-required methods involve creating new models and can be split into two types: training required and training free. Training-required methods involve training classifiers or simplified models to analyze the functions of different heads. Training-free methods, on the other hand, use scores or information flow graphs to understand the heads’ attributes. For example, researchers used Retrieval Score and Negative Attention Score to analyze retrieval heads and negative heads, respectively.
The researchers noted that current research on attention heads in LLMs faces limitations due to its focus on simple tasks, lack of comprehensive frameworks for head interactions, and absence of mathematical proofs. They think that future research should address these gaps by exploring complex tasks, improving experimental methods, developing robust interpretability frameworks, and integrating insights from the field of Machine Psychology. I think it's great that research is focusing on understanding how LLMs work — scaling parameters has worked well so far but doing so requires powerful hardware. Understanding the inner workings of LLMs could allow for a big performance leap in natural language processing (like we saw between recurrent neural networks and transformer models) without needing massive amounts of computing power.