
Text-to-video with realistic motion
Paper: Lumiere: A Space-Time Diffusion Model for Video Generation

Summary by Adrian Wilkins-Caruana and Tyler Neylon
Yesterday OpenAI announced an astounding new (closed) text-to-video model called Sora, named after the Japanese word for “Sky.” No one knows in detail how Sora works because there’s no paper or public interface as of today. However, a few small details suggest that they’re using ideas similar to a recent paper from Google Research; in particular, from the Sora announcement page:
Sora is capable of generating entire videos all at once or extending generated videos to make them longer. By giving the model foresight of many frames at a time, we’ve solved a challenging problem of making sure a subject stays the same even when it goes out of view temporarily.
Similar to GPT models, Sora uses a transformer architecture, unlocking superior scaling performance.
Let’s take a step back and look at both the (open, yay!) work from Google Research, as well as the recent challenges in text-to-video-land. The problem with videos from earlier models is that they’re weird. Take this video of Will Smith eating spaghetti, for example. If I pause the video, my brain clearly says “that’s Will Smith eating spaghetti.” But, the moment I unpause, the objects in the scene, such as the spaghetti and Will’s mouth, move in uncanny ways. AI researchers use the term temporal consistency for videos that manage to avoid this uncanny look. Today’s paper explains the source of these temporal anomalies and proposes a new way to generate videos with AI. Oh, and did I mention that the method was primarily developed by two interns (and one non-intern)?

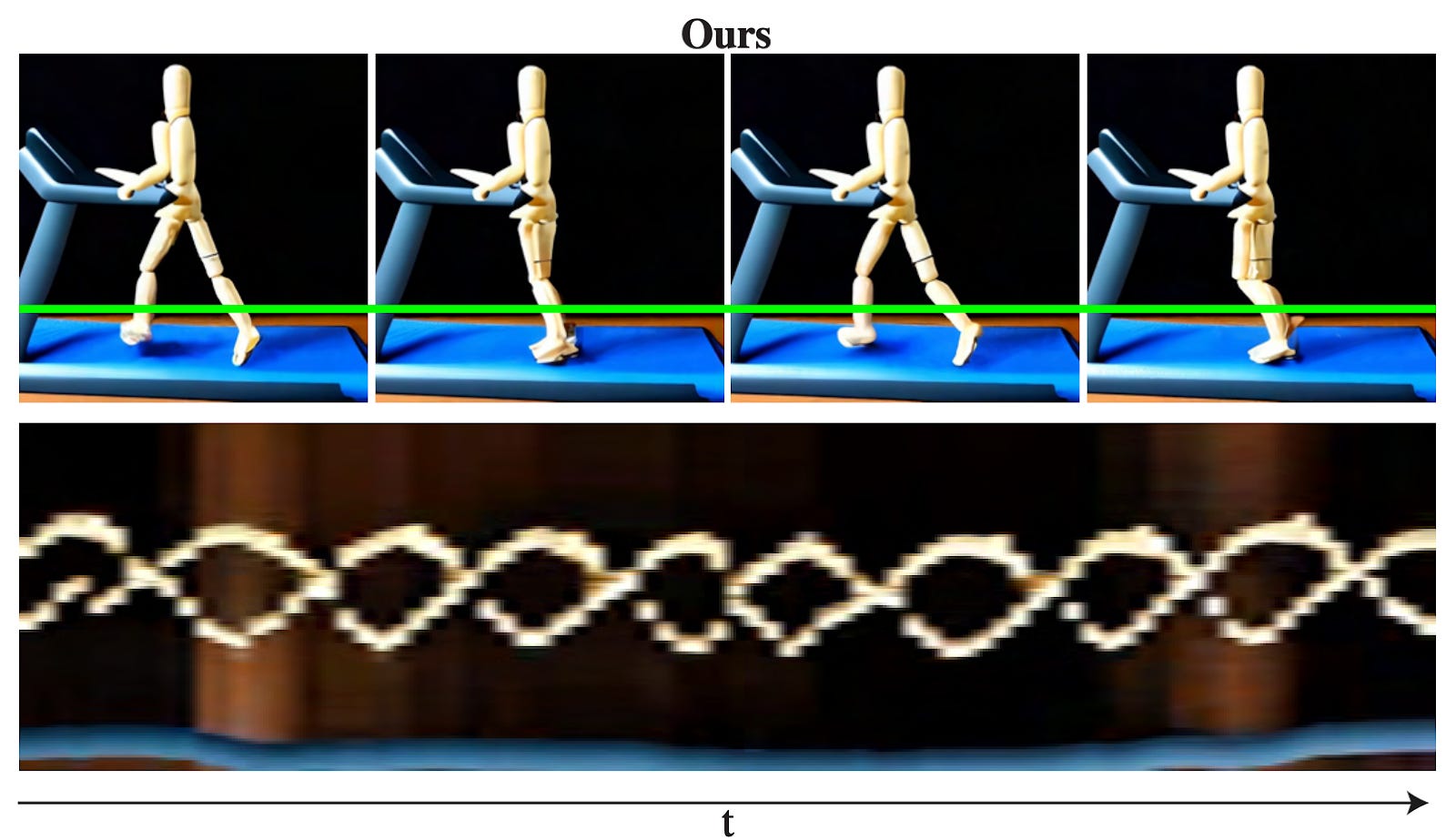
The concept of temporal consistency is one of those things that’s easy to spot yet hard to describe or measure. But the researchers have a neat way to visualize this. Here’s an image of four frames from an AI-generated video with poor temporal consistency. The green line tracks a slice of pixels across each frame in the video. These slices are then rotated and stacked horizontally in the bottom row of the image. The white double helix-looking thing corresponds to the white figure’s legs. We know legs can cross over each other in 3d space, but what we shouldn’t see are the legs jumping around — which is exactly what we do see in the middle of what’s called an X-T Slice. The X refers to the x-axis, meaning a horizontal slice, while the T refers to the time dimension.

Videos generated using the new method proposed by these researchers exhibit much more temporal consistency, as you can see below. This might sound like a small detail, but it’s crucial for generating high quality videos with AI.
The researchers hypothesized that past methods struggled with temporal consistency due to an optimization in previous architectures called temporal super resolution (TSR). The term super resolution is typically used to describe a model that adds more pixels, and thereby fidelity, to an image. However, in this instance, TSR means generating entirely new frames of the video. TSR has been a necessary part of video-generation methods because the base model — the model that actually generates frames — would be too computationally complex if it had to generate every frame. For example, to generate a 5-second video clip at 16 frames per second, using TSR means the base model only has to generate one fifth of the frames because TSR fills in the remaining 80% of the frames. But the TSR model knows only how to fill in the gaps — it doesn’t know the entire video’s context, and this lack of contextual understanding results in temporal inconsistencies.
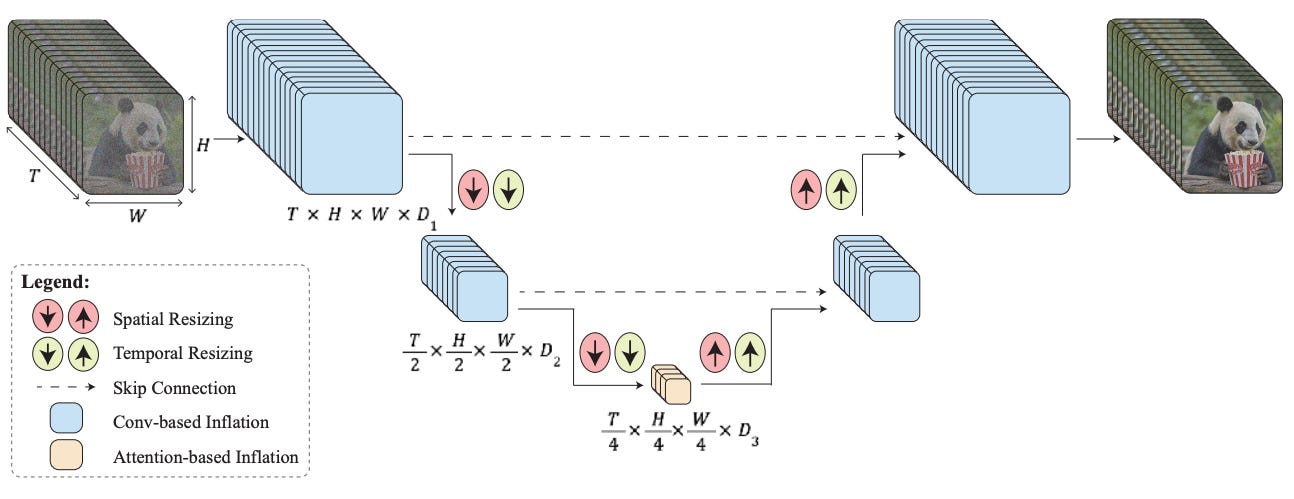
So, how can we do away with TSR without the base model’s computational needs exploding? The researchers noticed they could extend a technique that has been a part of neural networks for years: downsampling. The base model’s architecture is called a U-Net because it’s shaped like a “U” in the sense that the input goes through a series of spatial downsampling steps, and then a series of spatial upsampling steps that make the result the same resolution as the input. The downsampling reduces the size of the model, making U-Nets practical for image generation. However, since the input is a video and not an image, there’s an additional dimension — time — that can be downsampled. The image below shows how this downsampling is done in practice. Not only are the spatial dimensions (H and W) downsampled/upsampled (red arrows), but the temporal dimension (T) is too (light green arrows). The researchers call this a space-time U-Net (or a STUNet); for our 5-second, 16 fps video example, they would use this STUNet to generate all 80 frames.
In addition to STUNet, the researchers described one more technique they used to improve temporal consistency. To avoid excessive computation, U-Nets that generate frames of videos need to generate low-resolution frames of only 128x128 pixels. These low-res frames are then upsampled to a more reasonable 1024x1024 pixels using spatial super resolution (SSR). But SSRs can’t upsample all the video’s frames at once, so they work in batches. Unfortunately, this batching introduces more temporal inconsistencies, since artifacts may be introduced in the transition between the end of one batch over to the start of the next. To avoid introducing further inconsistencies, consecutive batches of SSR output overlap by a few frames. Then the two overlapping batches of frames are linearly combined, which helps smooth out the transition between the batches.
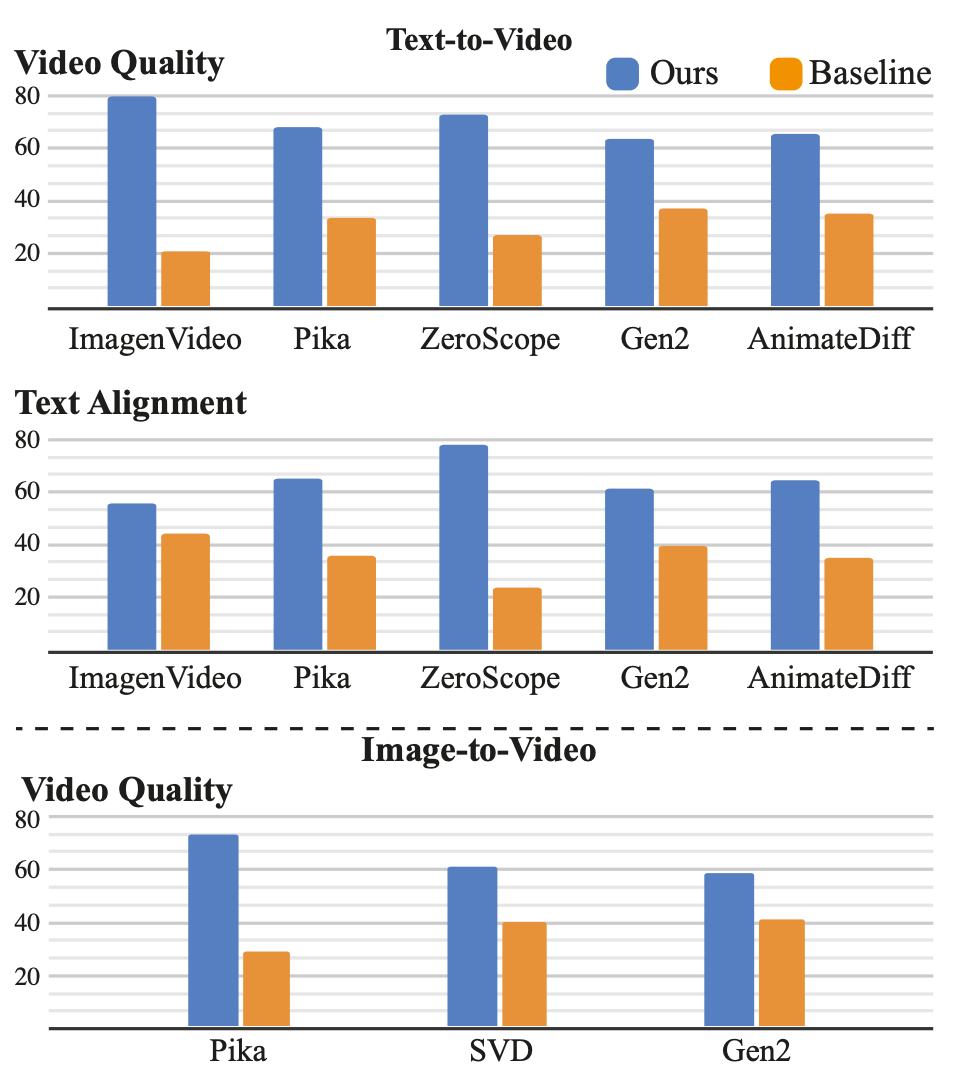
The researchers put these techniques together to create Lumiere, their state-of-the-art video-generation model. Lumiere can be used in a few different ways: text-to-video, image-to-video, stylized generation (i.e., creating a video in the style of another video or image), and inpainting, which is where a region of a video, such as the top-left quadrant, is missing and the model must fill it in. In a quantitative comparison, Lumiere outperformed seven other text-to-video methods, except for one method on one metric, but that method can only handle text-to-image tasks — not any of Lumiere’s other tasks. The researchers also asked users to subjectively judge whether they preferred Lumiere or another baseline in a head-to-head scenario. The users clearly preferred Lumiere to all other methods for video quality and text alignment. The y-axis here is the percent of users who preferred the output of Lumiere versus the comparison baseline model:
In my opinion, the results of previous video-generating AI attempts have been a bit underwhelming. I couldn’t look past things like poor temporal consistency. Seeing results from Lumiere for the first time made me say “yeah, I think this is believable now.” You can see some of the results for yourself on the paper's webpage. There are still aspects of Lumiere’s generated videos that don’t completely convince me, such as subjects moving in ways that don’t quite look realistic. Returning to Sora, we don’t know in detail how it works, but the quote above suggests that OpenAI may have also dropped the old TSR approach in favor of a more unified process that thinks in terms of both space and time as continuous dimensions. While both Lumiere and Sora create videos with some imperfections, they’re a giant leap forward, bringing us into an era where — at least for short video clips — the bright open sky’s the limit.