
Teaching LLMs to See
Let there be pixels!


When I look at the LLM market, I see a dominant player (OpenAI) keeping their cards close, and an arms race between the other players (Google, Meta, etc.) who share what they learn. OpenAI is widely regarded as having the best models at the moment, but it’s not clear they’ll maintain first place forever.
This dynamic seems fragile. Although OpenAI hasn’t released the architectural details of their flagship multimodal GPT-4 model, we probably understand most of the ideas behind it. Since similar models exist and work almost as well, it seems that the marketplace is not one genius and a few copycats, but rather someone with a head start amongst a group of peers.
In this kind of environment, we (the non-OpenAI plebeians) learn from those who share — and we learn a lot! I believe one of OpenAI’s big “secrets” at this point is how they’ve enabled GPT-4 to see (a feature which, as far as I know, exists but is still not publicly available). This is a big deal; the best LLMs act like brains in jars — no sensory input beyond the written word. Read on to learn how researchers are opening the eyes of LLMs for the first time.
— Tyler & Team
Paper: InstructBLIP: Towards General-Purpose Vision-Language Models with Instruction Tuning
Summary by Adrian Wilkins-Caruana
One of my favorite ChatGPT hacks that improves how well it can do something specific is to provide it with really detailed instructions. Even though ChatGPT probably won’t learn to solve your exact problem during training, the instructions can help it succeed. This is actually a behavior that’s specifically engineered into some language models. It’s called instruction fine-tuning: a way to turn a smart, well-spoken model into one that can also use what it knows and the instructions you give it to solve problems it hasn't seen before.
Unfortunately, lots of problems can’t be solved with language only; sometimes we need vision too. Today’s paper explores how a model that uses both text and images can be trained to solve novel problems, like answering the question, “What is unusual about this image?”

It’s obvious, right? The bicycle’s wheels look like watermelon cross-sections, which aren’t what bike wheels usually look like. To arrive at this answer, we needed to do several non-trivial things:
Synthesize the question.
Recognize that the main thing in the image is a bicycle.
Recognize that there is watermelon flesh and seeds where the wheel’s spokes should be.
Summarize all this information into a coherent answer.
To make an AI do this, the researchers developed a new model called InstructBLIP, which is specifically designed to be an instruction-following, image-text model.
The dataset used to train InstructBLIP contains instruction-following examples from 26 vision-language datasets. These datasets cover 11 different kinds of vision-language tasks, such as visual reasoning (like the watermelon bike), image captioning, and image question answering. Crucially, the researchers only used some of these datasets (13 out of 26) and tasks (7 out of 11) during training. They did this so they could then evaluate how good InstructBLIP was at solving tasks from these datasets that it hadn’t seen during training.
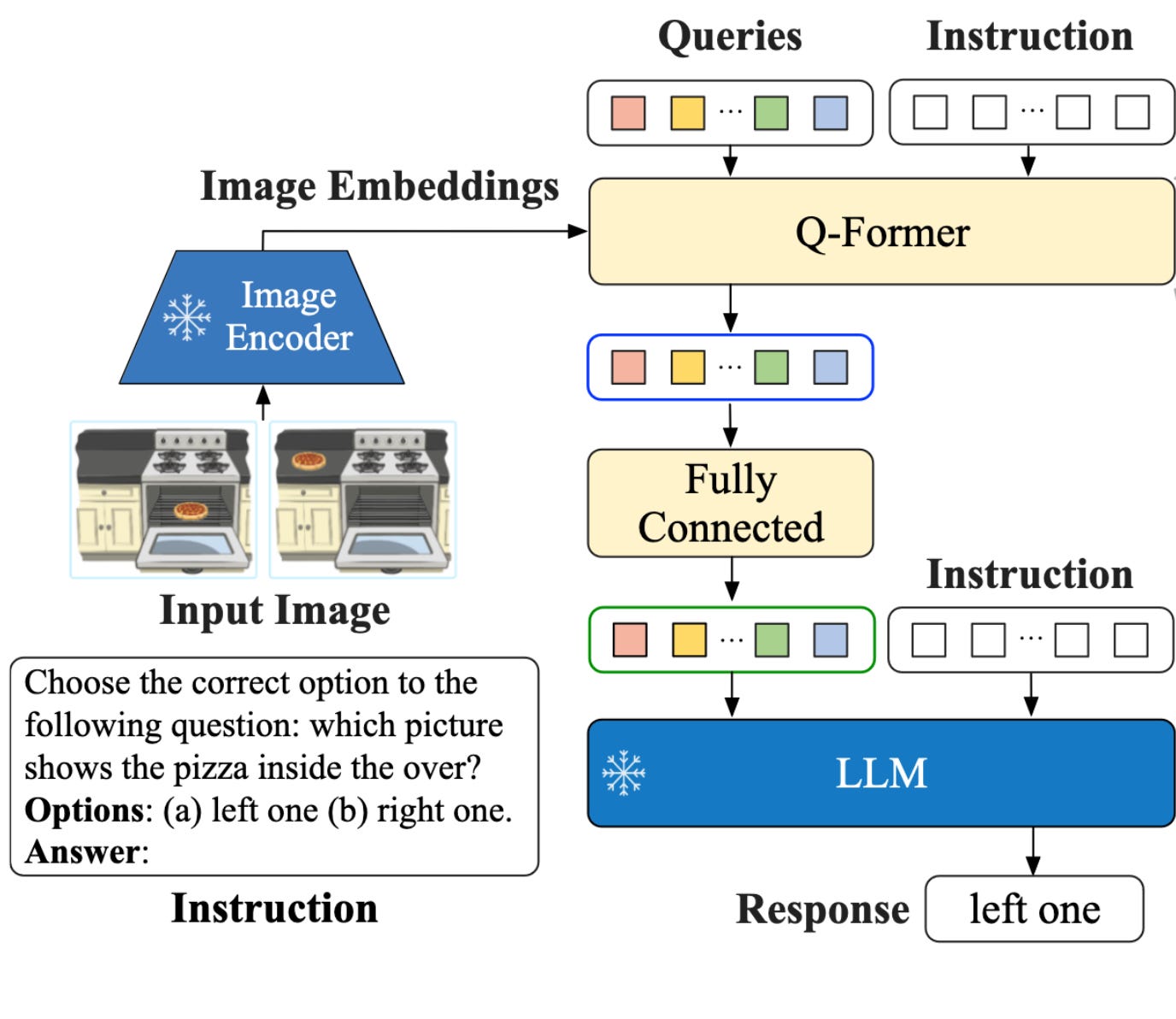
BLIP stands for Bootstrapping Language-Image Pre-training. As its name suggests, InstructBLIP is actually based on an existing model called BLIP-2. The main idea behind the BLIP family of models is an innovative way to make image-text models without having to train them from scratch:It uses pre-trained image-only and text-only models instead. The challenge with this approach is that these models can’t really talk to each other, so a lightweight model, called Q-Former, acts as an intermediary.
Q-Former translates the information in an image into info that the language model can understand. As we all know, an image is worth 1,000 words, which is too many to pass over to the language model. So, special query tokens tell Q-Former the kinds of image info that’s most important for the language model to know about.
I like to think of the query tokens as a punch-card, loading a program into Q-Former. Even though they’re not human-interpretable, I imagine the query tokens say something like, “Ok InstructBLIP, you’ve got to answer a question about an image that I can see but you can’t. To give you the best chance of answering correctly, I’m going to tell you about the salient, important stuff in the foreground, not the inconsequential stuff in the background.” In a sense, the queries are just like model parameters — optimized during training, but remaining static at inference time.
The image below shows InstructBLIP’s architecture, but the majority of the figure is actually just BLIP-2. It shows Q-Former passing information from a frozen image encoder to a frozen language model. Because InstructBLIP is simply BLIP-2 with added instructions, the InstructBLIP-specific parts of the figure are just the “instruction” blocks. This means that the visual info that Q-Former passes to the LLM is now instruction-aware, and the response generated by the LLM is also instruction-aware, so it can generate answers that are better aligned with the question.
On the other 13 datasets which weren’t used for training, InstructBLIP is consistently 10–30% better at different kinds of vision-language tasks than the non-instruction BLIP-2 model, and better still than Flamingo, a much larger vision-language model. Here’s an example that compares InstructBLIP’s instruction-following abilities with other multimodal models:

This is a good example of what it means to be an instruction-following model. Both of the other models clearly understand what the image is, but they’re just babbling on about the painting, while InstructBLIP just answers the question directly. Like BLIP-2, GPT-4, and Flamingo, InstructBLIP represents further incremental progress in making vision-language models more general-purpose and better at solving problems.