
Stable diffusion can simulate video games
[Paper: Diffusion Models are Real-Time Game Engines]

Summary by Oreolorun Olu-Ipinlaye
Video games are a joy to play — they’re a great pastime, hobby, or even job (competitive gaming). Developing video games, on the other hand, is no simple task: Game developers spend months handcrafting and hardcoding game states based on user inputs. But imagine if game states weren’t handcrafted and that we could use AI to generate scenes, scenarios, and characters based on user input. While this may seem like science fiction, recent advancements in computer vision generative models are bringing it closer to reality. The authors of today’s paper have shown that gen AI models can simulate dynamic, interactive game states.

Their model, named GameNGen (pronounced “game engine”), can simulate the 1993 release of DOOM to a high level of accuracy and at a visual quality comparable to the original game. But what type of model is GameNGen? It’s a diffusion model that they trained in a rather unorthodox manner. Instead of training it to just sequentially remove noise from images — as most diffusion models typically do — they trained it to generate the next frame in a sequence based on previous frames and user inputs/actions.
To do this, they needed a lot of training data. Their intention was to have GameNGen generate simulations that players would interact with, so they needed a lot of human gameplay data. As you can imagine, this could have been prohibitive due to the scale of data required, so they trained a reinforcement learning agent to play DOOM while collecting all their data from agent gameplay sessions — they called this agent play. One interesting thing the authors did was record agent sessions right from the start of training. They weren’t only interested in perfect gameplay sessions. which would have been archived after appropriate training. They were also interested in the early sessions where the agent played poorly because this mimics low-skilled human players.
With the human-like gameplay data collected, it was time to train GameNGen. At the core of GameNGen is a pre-trained text-to-image diffusion model — Stable Diffusion v1.4, which the researchers had repurposed by engineering the text-conditioning logic to take in user gameplay actions (e.g. key presses) rather than text. They did this by learning an embedding of each action. They also conditioned the model on previous frames, which they call observations. To do this, they encoded the frames into a latent space using the Stable Diffusion autoencoder, added some noise, and then concatenated them into latent channels. They then trained the model to minimize diffusion loss with velocity parametrization. The figure here illustrates these processes:
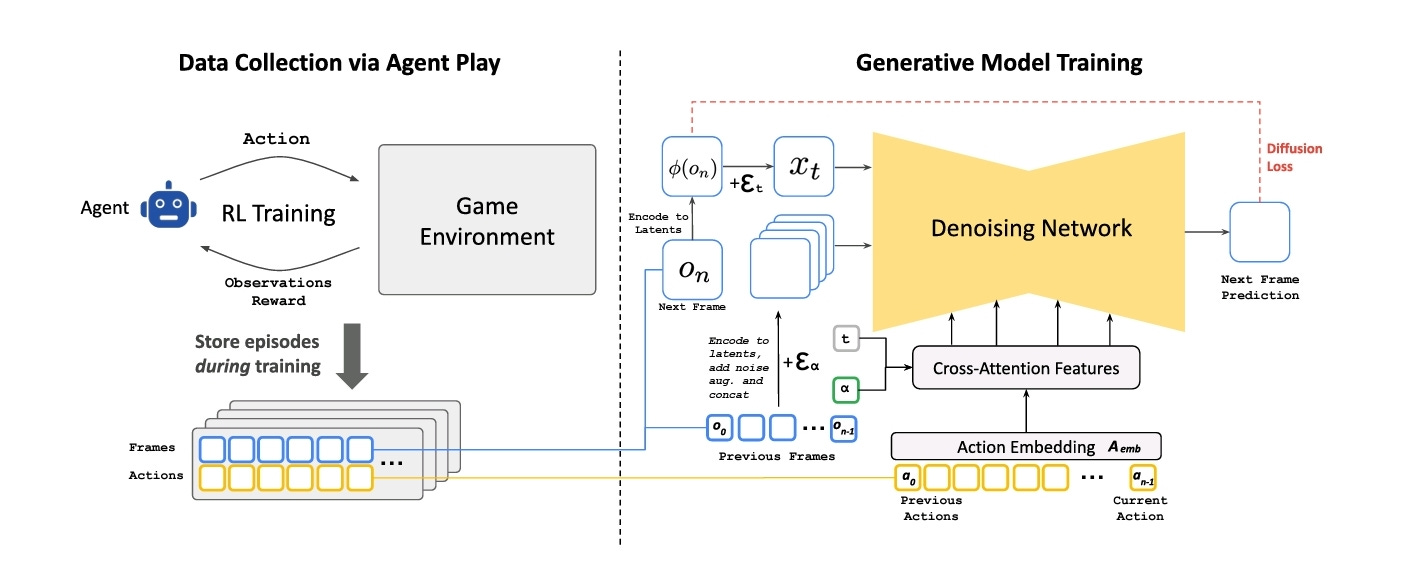
After training, the researchers found that GameNGen performed well in image-quality metrics with PSNR (peak signal-to-noise ratio, a measure of similarity between a true image and an approximate image) of 29.43 and LPIPS (learned perceptual image patch similarity, an alternative to PSNR that is more aware of the quirks of human perception) of 0.249, on par with what you’d see in a lossy JPEG compressed image with a quality setting of 20–30. When it comes to video quality, because of the auto-regressive nature of the task (the model needing to generate the next frame from its own predictions), the authors discovered that the generated game images looked worse over time due to the accumulation of errors between sequential frames. They also had people evaluate the simulations, asking them to identify real gameplay footage. The evaluators were only able to correctly identify actual gameplay 60% of the time!
The authors also ran some ablation experiments to evaluate the effectiveness of certain approaches they took during training. They found that using more past frames and actions helped improve the quality of simulations up to a certain point where the model reached a plateau. They also found that adding noise to frames during the training process was highly beneficial as performance took a big hit without it. They then compared training based on data collected by random user actions to training based on agent play and found that the model trained with agent-generated data outperformed that trained with random data, albeit only slightly in some instances.
GameNGen is, in my opinion, an incredible development and a precursor to potentially great leaps in the game industry. I believe that AI can complement traditional ways of doing things rather than completely replace them. So I think systems like GameNGen could complement traditional game development as a new feature in the game logic that ensures every player has unique experiences based on their playstyle — this would be particularly beneficial in open-world games. But we’re a long way from that as GameNGen simulated a game released in 1993. It’ll take significant advancements for us to simulate games like The Last of Us or Black Myth: Wukong.