
See yourself in new outfits, no changing needed
Paper: Diffuse to Choose: Enriching Image Conditioned Inpainting in Latent Diffusion Models for Virtual Try-All

Summary by Adrian Wilkins-Caruana

We’ve all been there: You find a nice top online and want to buy it, but you’re just not sure how it’ll actually look on you. Sure, you can search for more images — to see how the top fits other models and what it looks like in other environments — but it’s not really the same as actually trying it on. This is annoying for you, but it’s even more annoying for the merchant. If they could minimize this purchasing friction, they could sell more stuff. So it’s no surprise that Amazon wants to fix this with an interface they call virtual try-all (Vit-All), where an AI model renders the thing you want to buy, like a shirt or a couch, in the environment you want to use it. Here are some examples:

A new Amazon paper has introduced a method called Diffuse to Choose (DTC), which extends a prior Vit-All method called Paint by Example (PBE). PBE uses three inputs: a picture of the item (the reference, e.g., a shirt), a picture to render the item on (the source, e.g., a photo of you), and a masked source, which indicates where in the source the reference should be rendered (e.g., a line drawn around your shirt in your photo). A variational autoencoder’s (VAE) encoder maps the source into a diffusion model’s latent space, and during the diffusion process the model generates the reference (such as a shirt) in the masked area, guided by a encoded image vector of the item at the diffusion model’s bottleneck. This guiding vector, which you can think of as a conditional influence on the output, is an encoding of the reference (e.g., shirt image) that’s mapped by a multilayer perceptron into the U-Net bottleneck, and is combined with the masked source image (e.g., photo of you with your current shirt blacked out). The figure below shows this process, but note that, in this case, the subject is already wearing the reference item — this will make sense shortly.

The PBE method works well for the general problem of rendering any given thing in any other given image. But for the Vit-All use case, it has some limitations. Mainly, the only signal that conditions the generation is a relatively small encoding of the reference image. This condition has to compress an entire image into the vector equivalent of a single token, which is fine for “tiger” or “red apple,” but when it’s used for Vit-All, it loses the reference image’s details. Just imagine how many words you’d need to sufficiently describe the top in the figure above so that it could be accurately recreated — I think you’d need at least a paragraph.
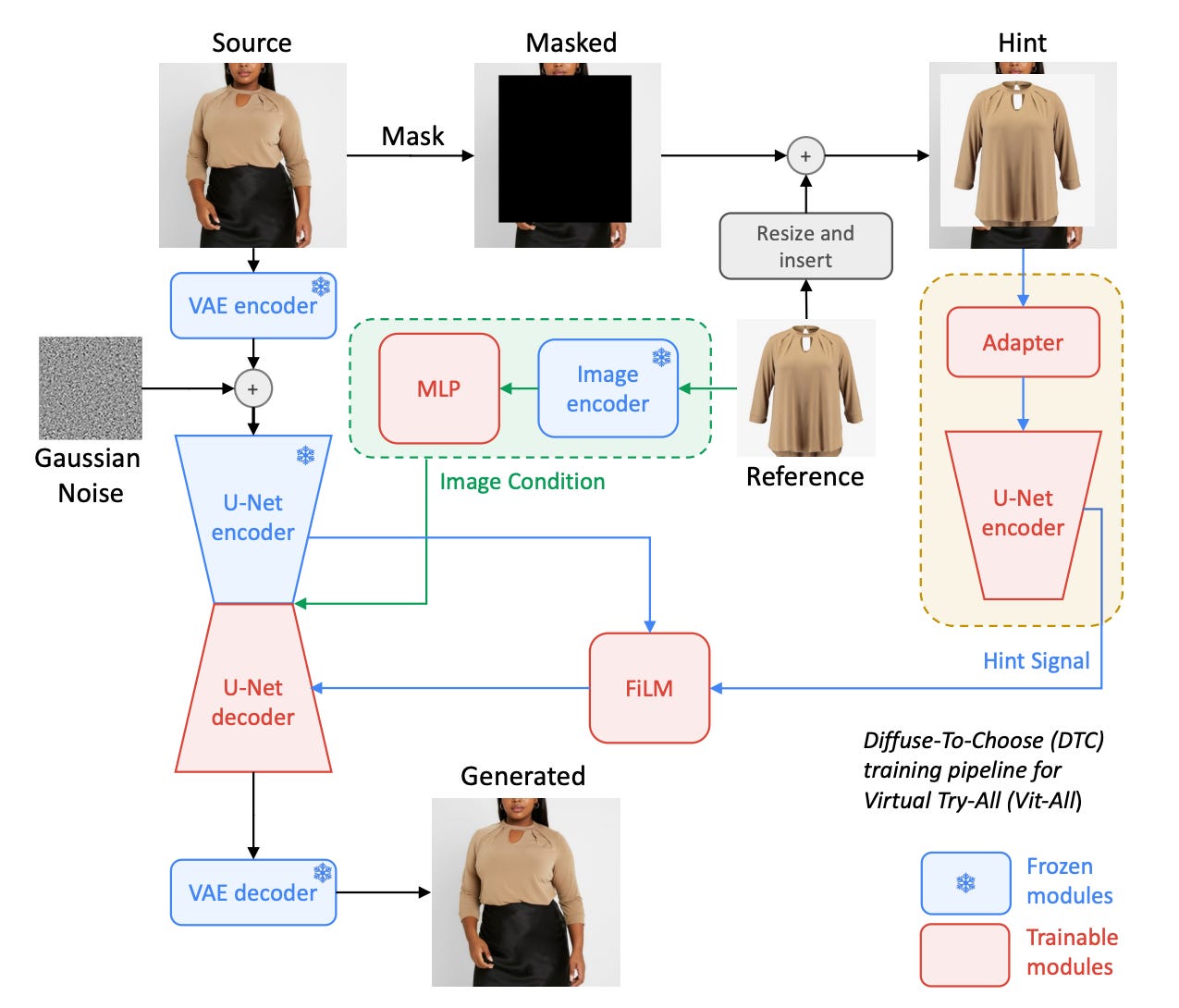
So, the DTC method extends PBE with a hint. Unlike the token-style reference representation, which acts as a conceptual condition, DTC’s hint is a pixel-style condition that helps preserve fine details of the reference image. First, the reference image is transposed onto a blank image canvas to fill in the region of the mask. This modified reference image is then processed by an adapter, which is a shallow convolutional network, and the result is combined with the VAE-encoded masked source before being encoded by a U-Net encoder, as you can see below. The red rectangles indicate weights that were trained for DTC, while the blue rectangles were pre-trained separately.

This hint vector is then combined into the main U-Net, the one that generates the final image. (If you’re familiar with ControlNet, this is similar to how ControlNet controls image generation, although the authors have slightly modified the integration into the U-Net.) To integrate the hint and source, the signals from the U-Net-encoded source image and from the hint need to be combined and provided to the U-Net decoder. The authors tried several methods here, and ultimately settled on a feature-wise linear modulation (FiLM), an established method for influencing neural network computation via a simple, feature-wise affine transformation based on conditioning information, which in this case are the encoded signals of the source and hint. The figure below shows the full system, including which parts have frozen weights (blue) and trainable weights (red).
One of the key advantages that a company like Amazon has for tasks like this is an abundance of data. In the PBE paper, the authors trained using a technique called self-referencing. Instead of compiling a dataset of source and reference pairs, self-referencing cuts out subjects from a source and uses the cut-outs as the reference. This works fine, but it can lead to some strange artifacts in the generated images unless specific measures are taken (e.g., extensive augmentation). But many online marketplaces contain images of products in isolation as well as in context, such as pictures of a shirt, and a separate picture of a model wearing the shirt. So the Amazon researchers didn’t need to rely on self-referencing, they just used the isolated images as the reference, and the contextual images as the source. That’s why they trained with source and reference images of the same product: because they could!
The researchers didn’t conduct extensive evaluations of their method, but they did conduct a qualitative survey: 20 subjects scored 30 samples, giving high scores when the item in the generated photo looked like the reference. They also scored how well the model blended the reference with the source. On a scale of 1 to 5 where 1 is better, the DTC method scored 2.9 and 2.5 on these metrics, while the PBE method scored 3.7 and 3.13, respectively. Another method, DreamPaint, scored on par with DTC, but it’s a few-shot method that takes several tries and ~40 minutes to generate a result, so it’s not really a fair comparison to a zero-shot method like DTC.
It won’t be long until we start seeing online stores begin to integrate Vit-All tools like DTC. Companies with lots of data, like Amazon, will have a competitive advantage, since their Vit-All method will likely perform the best. Perhaps it’ll be a premium feature at first, since diffusion models are still a bit slow, but as the technology improves, we’ll probably see interfaces like Vit-All in most online stores.
oh my —this is a great example of Goodhart's Law (making a target from a measure changes the measure). The methodolgy is superb of course, but it answers the question "can I see how this would look?" and not "will this fit me?"