
Running an LLM on a small customizable chip
[Paper: LlamaF: An Efficient Llama2 Architecture Accelerator on Embedded FPGAs]

Summary by Adrian Wilkins-Caruana
If you open the ChatGPT app on your phone, you’ll find that the system can reply to questions about as quickly as you can type them. This is possible thanks to the miracle of the internet: Your queries are whisked away to a data center where a big, powerful computer — the one that’s actually running the LLM — produces the response. One reason this is necessary is that your phone’s processor isn’t fast enough to handle LLM responses in real time. But our phones are quite incredible devices that can seemingly do anything, so why can’t they run LLMs? Today’s summary discusses some of the challenges and some clever solutions to them.

Not all processors are made equal. Some are general-purpose, while others are highly specialized for specific applications. You can think of general-purpose processors as being like craftsmen and of specialized processors as factories. Because they’re specialized, factories can make things more quickly — but with less flexibility — than craftsmen. Part of the challenge in making a factory-like processor for LLMs is finding ways to set up the factory to maximize efficiency, which is exactly what Xu et al. have done in their recent study. Specifically, they’ve efficiently implemented Llama 2 on a field-programmable gate array, or FPGA (which is a type of factory-like processor).
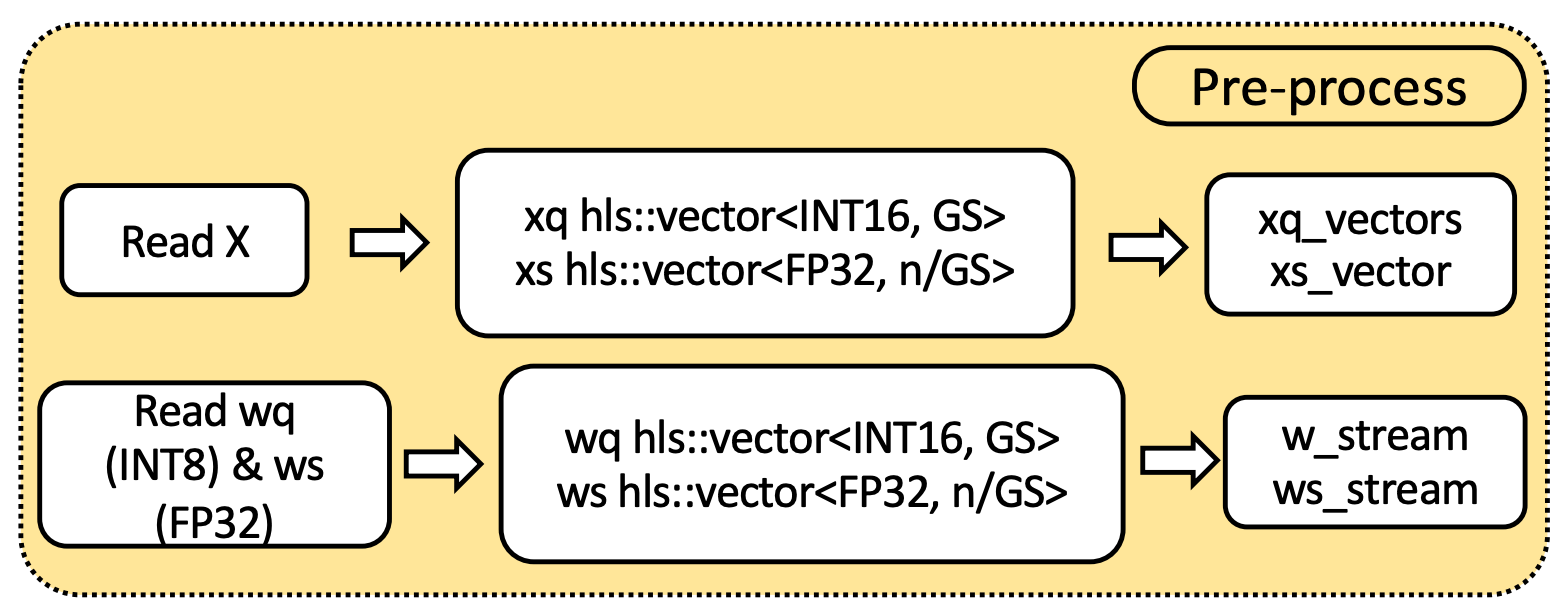
Their approach has many identical blocks for all the layers in Llama 2’s forward pass, and each block has three stages. The first stage, called pre-processing, is shown in the figure below. This stage is responsible for reading input vectors X — which might be input tokens or outputs from another layer — and preparing them for the next stage, and is responsible for reading the weights for that layer. The inputs and weights are quantized, and are accompanied by a scaling factor (xs and ws for the input and weights, respectively). Quantization is a way to compress the 32-bit floating point inputs and weights into less space (8 bits), and the scaling factors are needed to undo the compression. There are two important details here: First, the weights are streamed rather than read all at once, and second, the quantized values are cast from 8-bits to 16-bits (we’ll see why these details are important in the next paragraph).
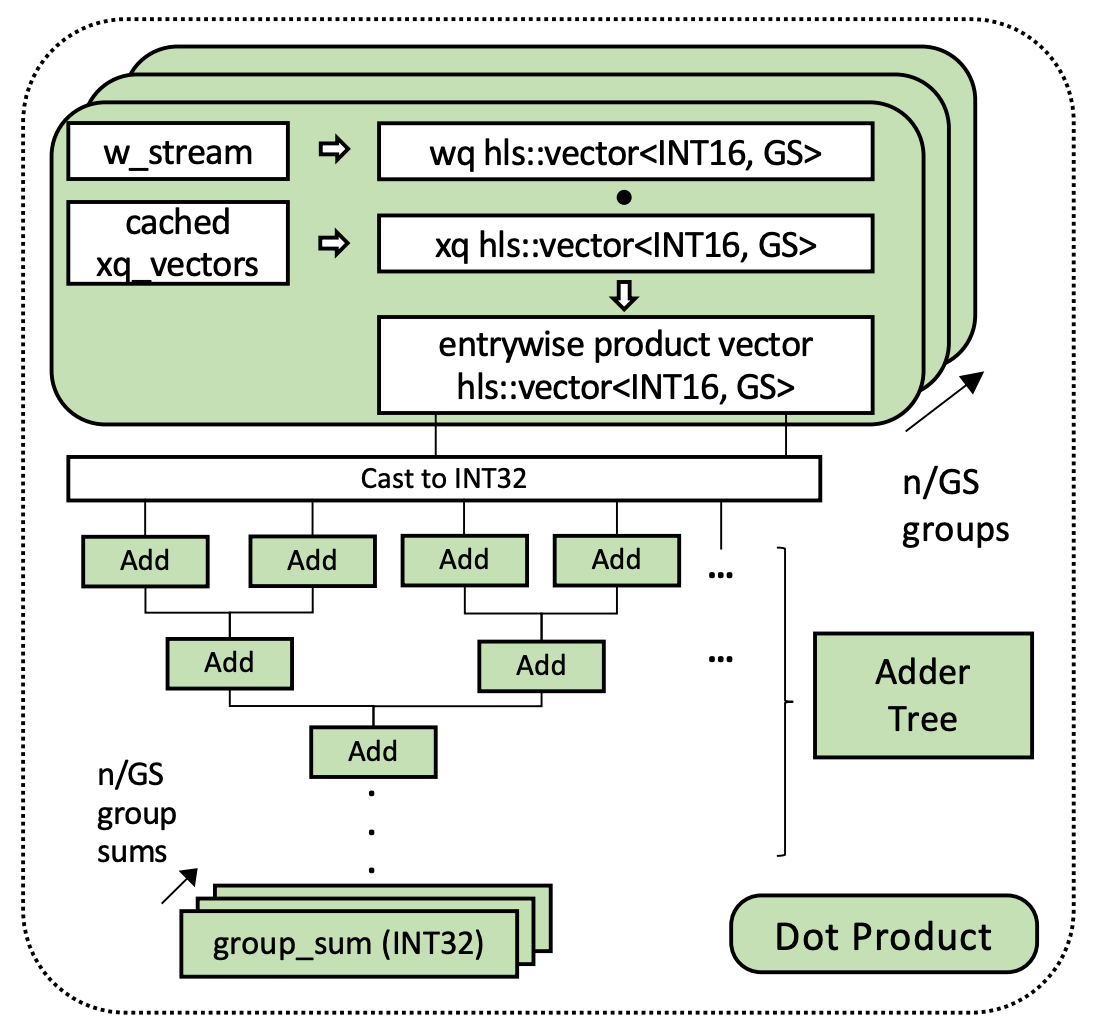
The next stage implements the fundamental operation of neural networks: the dot product, which is essentially some “multiply” operations followed by some “add” operations. The stage is called a quantized matrix-vector multiplication because it’s specifically designed for the quantized inputs and weights. As the 16-bit weights are streamed into this stage, they’re multiplied by cached 16-bit input vectors. Even though the data in the inputs and weights doesn’t exceed 8-bits, the result of the multiplication might overflow an 8-bit data type, so the 16-bits ensure there’s enough capacity to prevent that. These results are then accumulated together by adding and combining pairs of results. This can be done efficiently in parallel using an adder tree like the one in the figure below. Preventing overflow is important here, too, so the multiply-results are cast to 32-bits before summing.
The final processing stage, called accumulate, is pretty straightforward. It undoes the quantization by first casting the 32-bit integer group sums to a 32-bit floating point format, and then scaling the results from the group sums by this value. These three stages — pre-processing, dot product, and accumulate — are the building blocks of the Llama 2 FPGA implementation, but another key detail is the orchestration of data through these stages. Because the weight values are streamed, the execution of the blocks can happen while weights are being copied to and from memory. For example, the figure below shows how asynchronous orchestration shortens the overall duration of the memory-copying (blue) and processing (orange) stages.

In their tests, Xu et al. measured huge gains in efficiency using their FPGA-based implementation. They used a special chip called a system-on-a-chip, which combines both a general-purpose processor and an FPGA. Compared with using a general-purpose processor, the FPGA-based implementation performed 23.4x more operations per second and 15.8x more tokens per second! The FPGA-based approach was also 6.1x more energy efficient.
These margins demonstrate just how much more efficient task-specific processors are than general-purpose ones. This is why lots of new processors are shipping with dedicated AI accelerators. These processors are highly-efficient at multiplying and accumulating, but not much else. As such accelerators become more powerful and as researchers get better at improving the performance of smaller LLMs, we may eventually be able to run ChatGPT on our phones without needing internet access.