
Real-time scene rendering from a few photos
Paper: 3D Gaussian Splatting for Real-Time Radiance Field Rendering

Summary by Adrian Wilkins-Caruana
Imagine playing a high-definition (1080p) video game that takes place in your back yard. The environment you see in the game isn’t a 2d projection of some predefined 3d assets, but generated from two or three photos you provided of your yard. The experience is so realistic, you don’t even notice the screen refreshing (it happens so quickly that it’s imperceptible).
What I’ve just described is a bit of a stretch from what has been technically possible. Neural networks can generate 3d scenes from photos (these are called neural radiance fields, or NeRFs), but they typically can’t generate them in HD or fast enough for real-time rendering (i.e., over 30 frames per second). But with recent innovations, researchers have found ways to represent scenes more efficiently, optimize them better, and render them faster. This means we can now experience incredibly realistic, high-definition scenes from any viewpoint in real-time. It's like stepping into a new era of visual media where you’re in control of what you see.
Before we dig into the innovations presented in this paper by Kerbl et al., let’s quickly recap what a NeRF model is. It’s a volumetric rendering technique that uses a fully-connected neural network to generate novel views of complex 3d scenes from a few 2d images of a scene. It’s trained to use a rendering loss to reproduce input views of a scene. Effectively, the neural network learns to interpolate between the 2d views to render the complete scene based on its understanding of the volume and color at particular points in 3d space.
The two main issues with this technique, particularly for real-time rendering, are that big neural networks can be slow, and that the slow network needs to be used to determine color and density for many, many points (samples) in 3d space. The main way Kerbl et al. overcome these limitations is to not use a neural network at all! Their technique has three main components: representing the scene using 3d Gaussians (each being a point, color, and what you might call a “fuzzy radius”), optimizing these 3d Gaussians, and efficiently rendering 2d views of the scene from the 3d Gaussians. Let’s dive into understanding these components, which you can see in the figure below.
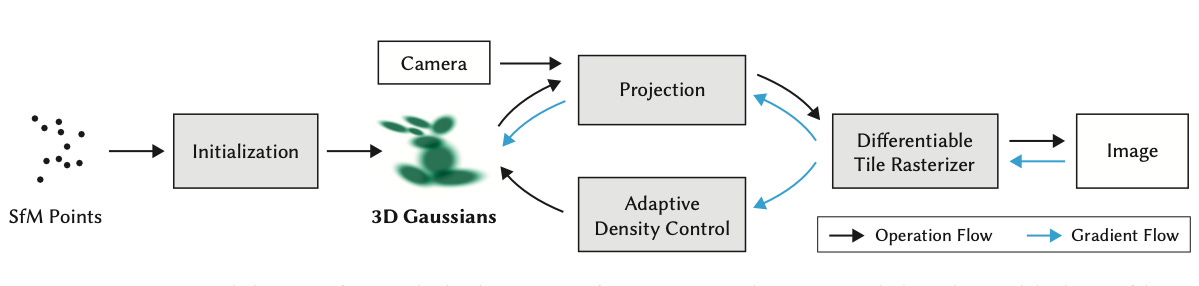
To start with, a standardized method called SfM (Structure-from-Motion) converts a set of images into a sparse 3d point cloud, which is on the left in the figure above. From here, we need to generate some representation of the scene that the model understands and can operate on. The authors of the 2020 NeRF paper achieved this with a radiance field, which assigned individual values for color and density to every 3d point in the scene. A view of the scene can then be rendered by “splatting” little dots of color onto the frame based on color and density values produced by a NeRF model of the objects.
Kerbl et al. did much the same, except instead of using single values to represent the radiance primitives, they use 3d Gaussians, which are a smooth, differentiable alternative (“differentiable” meaning each Guassian has a derivative as a function of x, y, and z; useful for optimizing the loss function!). They also didn’t assign Gaussians to every point in space — they only used a finite number of sparsely located Gaussians throughout the scene. They achieved “splatting” by blending the color and density info of overlapping 3d Gaussians, resulting in 2d ellipses on the image.
Initially, the shape and position of these Gaussians isn’t great, as you can see here:

This example shows how optimization improves the 3d Gaussian representation. This means optimizing the 3d position, opacity, covariance matrix (i.e., the shape of the Gaussian), and color. Each iteration step involves updating these parameters and then using them to render the scene before calculating a loss that captures reconstruction error (L1) and perceived similarity with a ground-truth image (structural similarity, or SSIM). Throughout optimization, the number of Gaussians can change — some are removed when their opacity goes below a certain threshold, some are cloned (doubled at the same size) when the Gaussian under-reconstructs the region, and others are split (cut into two smaller pieces) when they over-reconstruct the region.
The last piece of Kerbl et al.’s method is the differentiable Gaussian rasterizer, which is what turns the 3d Gaussians into a 2d image representing a view of the scene. As you might imagine, this step needs to be really fast since we need to rasterize a view for every optimization step — and that’s on top of computing gradients and updating weights. To achieve this, the researchers (who I’m convinced are computing wizards) rolled up their sleeves and wrote super efficient GPU code (i.e., CUDA kernels) that renders the image and computes the gradients (i.e., forward and backward passes of the model). They also used several neat optimizations, such as only rendering Gaussians that are in the 2d frame, using approximate blending of overlapping but semi-transparent Gaussians, and stopping rasterization of pixels once they reach a saturation threshold.
Here’s an example of some 2d scenes rendered using this method (middle column) shown alongside the ground-truth images (left column) and the next-best, neural-based baseline (right column.)

Their method doesn’t perform miracles, though. For example, if the two provided perspectives of a scene aren’t sufficient to disambiguate parts of a scene, then the model won’t know what’s actually there (i.e., it can’t see through walls). The 3d Gaussian also occasionally generates some points of color that appear to pop back and forth in space between frames. And, in general, radiance field models are only a “ray-marching” approach, which means they don’t capture things like the reflection or diffusion of rays. Be that as it may, a real-time neural renderer is a big deal, and I’m excited to see how people use this technology for things like gaming or 3d modeling!