
Pull up a chair, type your password ... I won't peek
Paper: A Practical Deep Learning-Based Acoustic Side Channel Attack on Keyboards

Summary by Adrian Wilkins-Caruana
Imagine you’re sitting at Starbucks, sipping a delicious pumpkin spice latte as you open your MacBook to start working. It’s been a few days since you last checked your email, so your browser prompts you to enter your password. Without much thought, you discretely enter your password, careful to make sure nobody can see your keystrokes. But little do you know that, as your fingers clack away on your laptop’s keyboard, they’re transmitting your password to anyone who’s listening carefully enough.

Today’s paper explores a type of computer security attack that you may not have heard of before: a side channel attack (SCA). This attack takes advantage of seemingly inconspicuous channels or mediums that are created as a side effect of the main operation of the attacked system, such as the sound your keyboard makes as you type your password. In their paper, Harrison et al. show how a neural network can analyze digital audio recordings to recognize which keys are pressed based on their sound.
They generated the neural network’s training data by simultaneously recording MacBook keystrokes (which keys were pressed) and the sounds they made. They actually made two separate audio recordings: one from a nearby smartphone microphone (like in the figure below) and another from the audio that was transmitted from the laptop’s microphones to another computer via Zoom. Then, after some data processing, they were able to train a neural network with supervised learning to classify which key was pressed based on the audio signal.

The researchers tried to classify the 36 alphanumeric keys: A–Z and 0-9. They separated the long audio snippet of all the recorded keypresses into many smaller recordings of individual keypresses using an automatic signal-processing algorithm (a fast Fourier transform followed by applying a threshold). They also converted the audio waveforms into mel-spectrograms, which is a way of representing 1d audio recordings as 2d images, where the x-axis represents time, the y-axis individual frequencies, and the brightness the intensity of each frequency at a given time (see below).
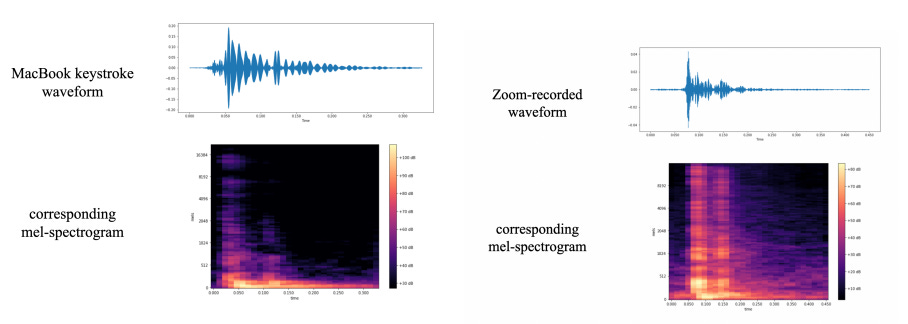
The authors then trained two separate models to predict the keystrokes, one for the phone recording, and another for the Zoom recording. They used CoAtNet, a near-state-of-the-art, ImageNet-classifying architecture that uses a combination of convolution layers and self-attention to predict the probability of each of the 36 possible keypresses. After training, they measured the model’s ability to classify 180 unseen keypresses from the same machine as the training keypresses. Overall, the classifier was 95% accurate on the phone-recorded data, and 93% accurate on the Zoom-recorded data as measured by an average F1-score across all the keypresses. Testing the classifier on only 180 keypresses is perhaps not quite enough to definitively say how good the classifier is but, on this limited sample, the model seems to be generalizing well to unseen keystrokes.
The authors don’t comment on whether their models generalize outside of their notably sterile test environment (a laptop on a desk in a small, quiet room) so it’s ✨ Speculation Time! ✨ Even though the authors didn’t test whether their models (phone and Zoom) can generalize to other MacBooks, I’d wager that they would actually generalize pretty well to other similar MacBooks, and for typing at varying speeds, forces, and pressures. But I’m not sure the mobile-recorded model would fare as well in other acoustic environments (e.g., different desk material or typing with long fingernails). On the other hand, I suspect the Zoom-based approach would be much more consistent across environments, since the laptop’s microphones would pick up on the internal acoustic vibrations of the device itself, which wouldn’t vary so much in other environments.
Another scary thing to consider is that an audio SCA model doesn’t need to be very accurate at all to be useful to an attacker! For example, if the model was being used to crack the password “learnandburniscool,” it wouldn’t matter too much if the model makes a mistake on one of the characters, since a password-cracking algorithm could easily correct the mistakes using a dictionary. The algorithm could even exploit some of the common mistakes the model makes when it makes a second guess — e.g., the model sometimes predicts a 6 when the key was actually a 7, so let’s try 7 next.
The audio SCA demonstrated in this paper is just one type of SCA. Others include analyzing the power consumption of devices or the electromagnetic waves they emit. For example, this recent Computerphile video discusses how the brightness of an LED on a security card scanning device can be used for an SCA. I think it’s the responsibility of the device manufacturers to ensure that their products aren’t susceptible to such attacks. Imagine how Google would respond if someone discovered that their Chrome browser was leaking everyone’s passwords due to an obvious or predictable design flaw —they’d no doubt ship a patch immediately! The same considerations should be given to SCAs like the one demonstrated by Harrison et al.