
Predicting depth data from a single image
[Paper: Depth Anything V2]

Summary by Adrian Wilkins-Caruana
Last week we discussed a new method for resolving the 3d structure of a scene from two perspectives or photos of it. I mentioned how our brains can do this too, using the images from each of our eyes to perceive things in 3d. But what if you close one eye; do you lose your ability to see in 3d? The answer is a resounding “No!” Our brains can still perceive a lot of 3d info from a single, unmoving image. In fact, we do this all the time when we look at photos and use things like occlusions and shadows to infer depth and scale. This is why we find optical illusions like the Penrose Triangle perplexing.

If our brains can perceive the depth of objects using information in an image, then computers probably can, too. This process, known as monocular depth estimation (MDE), has been an active area of machine learning research for some time now. Before discussing that research, let’s learn a bit more about MDE. The figure below shows relative depth estimates on some images predicted by a model called Depth Anything V2. The redness/blueness of the results indicate parts of the image that are closest/farthest from the camera, respectively.

Depth Anything V2 is an impressive model. But the story of its success isn’t just “more data” or “bigger model.” To appreciate it, we first need to review how we got here:
MiDaS is an impressive MDE method that broke onto the scene in 2020. It predicts the relative depth of pixels in an image, and was trained using supervised learning on a dataset of over a million images with depth labels. When it was released, it was the state of the art for MDE.
The MiDaS team made incremental improvements, and its third iteration was the state of the art until this year. Despite its success, it struggles to predict depth on images that are different from its training data (that is, zero-shot prediction).
In January, the researchers behind Depth Anything V2 released Depth Anything (V1). While this model introduced several innovations to help zero-shot generalization (like augmentation and a special loss term), its real innovation — and the one that ultimately helped improve its zero-shot generalization — was its use of unlabeled training images. (I’ll explain how this is possible shortly!)
Finally, we now have Depth Anything V2 a short six months after V1. In terms of data, V2 took a drastic approach, ditching labeled data entirely for synthetic data! As we’ll see, it improves upon V1 in a number of ways, including fine-grained details, accuracy, and its ability to not be fooled by confusing surfaces like windows and mirrors.
From this MDE timeline, it’s clear that training data has played a pivotal role in MDE iteration. If you think about this for a moment, it kind of makes sense. The depth “labels” — which are generated from a number of depth-sensing sources like RGBD cameras (yep, the “D” is for “depth”) or LIDAR — can have a lot of issues, like not being as high-resolution as their corresponding image, or they might be noisy or just not very accurate. So MDE models trained on this data will be fundamentally limited by it.
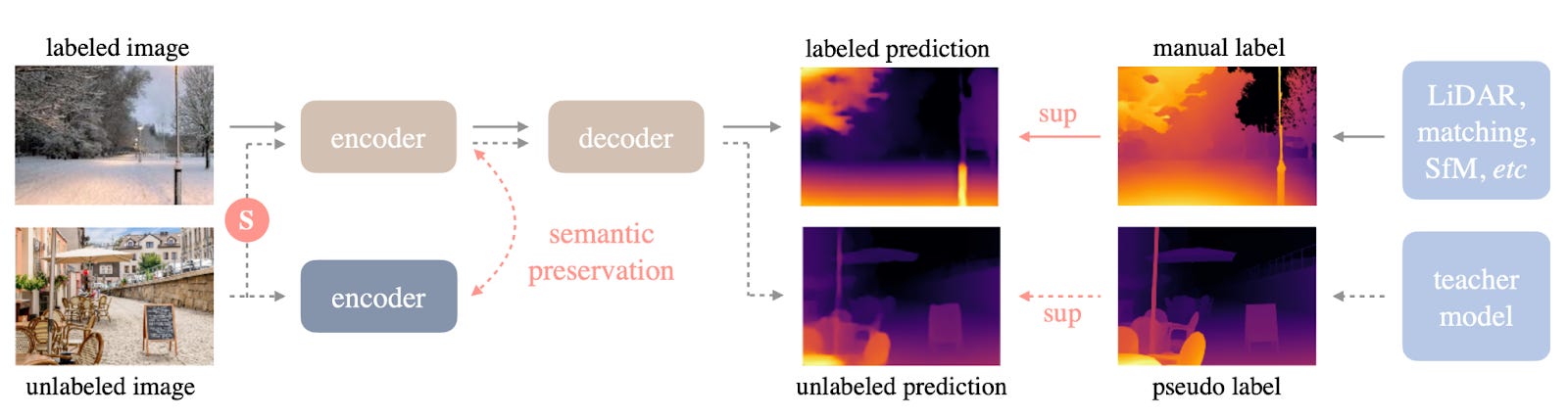
In Depth Anything V1, the researchers came up with a way to use unlabeled images (i.e., regular images) as training data. To do this, they first trained the best model they could on the labeled dataset, then used this model to predict the depth on unlabeled images, and used these predictions as pseudo labels. This is called a student-teacher approach, where the big model trained on the labeled data is the teacher, and its knowledge (i.e., predictions) are used to teach the student model, which is nice to have because it’s much smaller (and so more convenient to work with) than the teacher model. The reason I’m taking time to specifically mention this aspect of V1 (and not any of the other clever tricks they invented) is because it’s crucial for V2. The figure below shows a rough schematic of the student-teacher process, where the solid lines indicate the flow of labeled data/images, and dashed lines represent the flow for unlabeled ones. (The “semantic preservation” is one of the tricks I mentioned, and it prevents the encoder from varying too much from when it was trained on labeled data).
So, Depth Anything V1 used unlabeled data to address the zero-shot generalization problem of MiDaS. V2 goes further to improve the accuracy and robustness of the predictions by extensively using synthetic data, which you can think of as renderings of 3d scenes — like from a video game — where the depth can be measured using the information in the 3d model. While it sounds insane, the choice to completely ditch labeled data actually makes a lot of sense. If the labeled data isn’t accurate enough, just replace it with highly accurate synthetic data, right? Well, there are two very good reasons not to do this: Synthetic data is typically quite different from and far less diverse than real imagery. So there’s a large domain shift between synthetic and real data. But combining synthetic data with both the student-teacher approach and unlabeled real images alleviated these two problems and yielded a model that’s both accurate and has good zero-shot generalization.

I think the best way to demonstrate why using only synthetic data is so helpful is to take another look at the pictures of the bridge and the room above. In the bridge image, there's a lot of fine-grained detail that a depth sensor might not be able to capture. And, in the room image, notice how the depth indicates the window, not the objects that you can see through the window. This is the kind of depth detail that’s really difficult to accurately capture in the real world.
“But Adrian!” I hear you screaming, “Surely there must be some value in all that labeled data.” Well, the Depth Anything V2 authors thought that too. So, when training the student with the pseudo labels on unlabeled images, they tried including a little bit of labeled data — the highest-quality labeled data they had. But they found that mixing in just 5% labeled data (keeping 95% synthetic) seemed to harm performance, particularly for fine-grained details. You might need to squint, but the figure below shows that the model that used synthetic data only (middle column) is definitely superior.

I really like the authors’ approach in the Depth Anything V2 paper, and I think their model’s results are quite impressive. It’s a very “outside-the-box” idea, and I’m curious to see if researchers in other domains can use similar ideas to make other AI breakthroughs. I highly recommend taking a look at the paper’s webpage to see more examples of what they accomplished.
I’ll leave you with one more Depth Anything V2 example below, one that yet again shows how impressive it is while also being a bit of a contradiction to the authors' claims of robustness. Specifically, they claim that the model is quite robust to domain shift (which it certainly is), but they use these depth-prediction results on drawings and paintings (shown below), among others, as an exemplar of this idea. But what is the correct result in this case? Should it be a realistic depth (as Depth Anything V2 predicts) or just the depth of a planar surface, since the paper or canvas is presumably flat? I think it should be flat, since this would be more in-line with predicting windows instead of what’s shown through the window. What do you think?
