
Paper: Any-to-Any Generation via Composable Diffusion

[Note: If you’d like to learn about LLMs, we have a one-day workshop next week! Tyler Neylon and Gabriel Bianconi will teach how to set up and customize an open source LLM.]
Summary by Adrian Wilkins-Caruana
If you haven’t tried it yet, Stable Diffusion is an incredibly powerful tool that turns text you write into an image of what the text describes (text to image). There are other kinds of diffusion models, too: text-to-video, image-to-video, text-to-audio, etc. But wouldn’t it be nice if we could use a single model to generate any kind of media from any kind of media? Well, Tang et al. have released the code for their Composable Diffusion (CoDi) model, a cross-modal diffusion model that can generate media using any arbitrary combination of image, video, audio, and text!

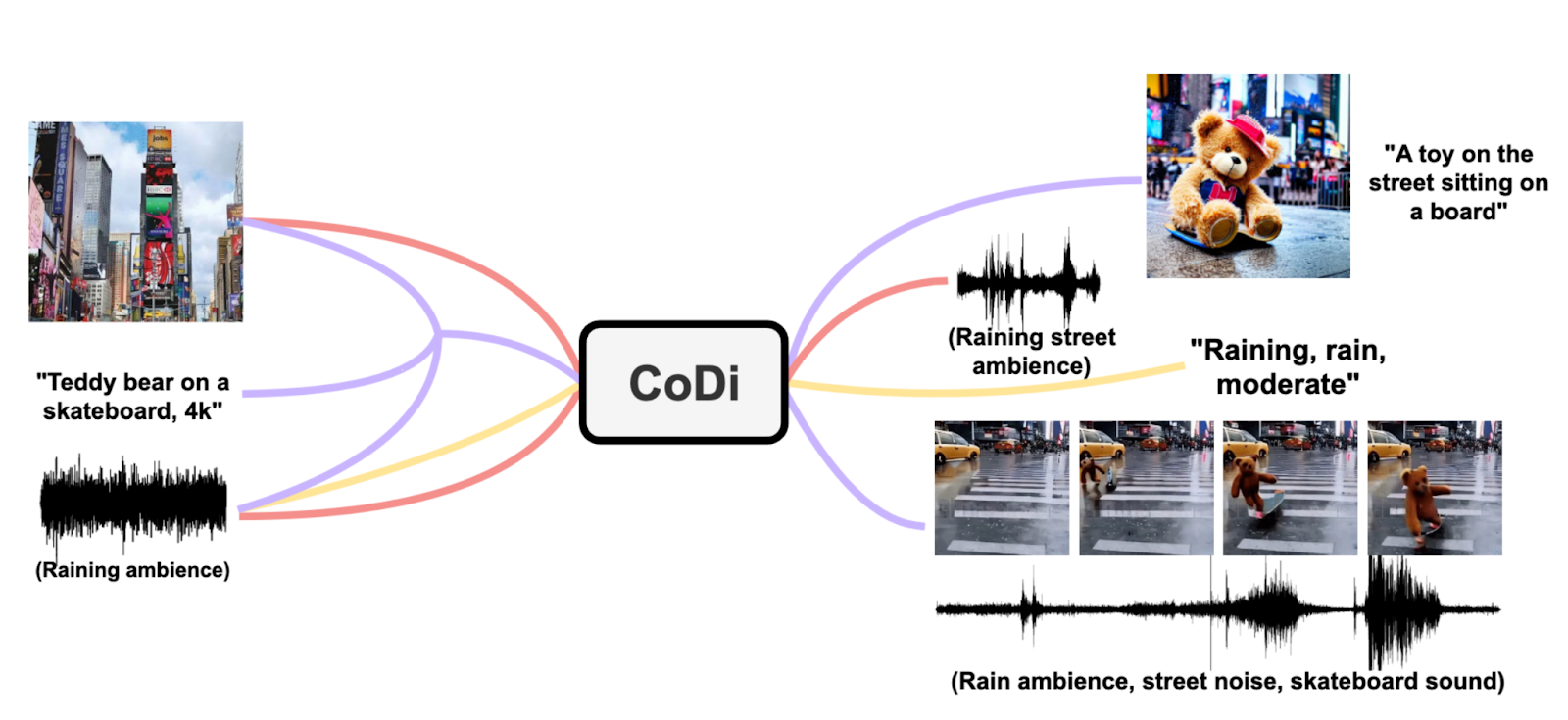
Before we dive into the paper, let’s look at some examples of what CoDi can do. CoDi isn't limited to modality pairs: It can combine several modalities in many different ways. The image below shows:
[image+audio]-to-[audio] (red)
[audio]-to-[text] (yellow)
[image+text+audio]-to-[image+text] (purple, top right)
[image+text+audio]-to-[video+audio] (purple, bottom right)
Unlike a typical diffusion model, which has a prompt encoder and a generation network (called a UNet), CoDi has separate encoders and UNets for text, image, video, and audio (8 total). Each encoder is trained to generate similar encoded representations (which we can imagine as a vector of numbers) of the things in their input — this is called “alignment.” For example, the text-encoding of “a red car” and the image-encoding a picture of a red car should result in a similar vector of numbers. To align the encoders, the researchers first trained CoDi with text-image, text-video, and text-audio example pairs. (These pairings all contain text, which means they didn’t need to train with image-audio pairs, which are hard to find.) The researchers call this technique Bridging Alignment, since the text data bridges the others, as shown in the figure below.

After aligning the encoders, the researchers had to align the UNets that generate latent variables (which are also like vectors of numbers) that get decoded to produce the final text, image, video, or audio. The UNets need to be aligned so that when they decode the text-prompt-encoding of “a red car,” we don’t get a video of a Smart car and the audio of a racecar.
Different UNets talk to each other via cross-attention weights, and CoDi uses these weights to align the UNets. These weights need to be trained to be useful, which the team did with another set of encoders (called “environment encoders”) for each data format that encodes the latent variables into a shared format. The researchers then trained the cross-attention weights in a process similar to the Bridging Alignment:
Train the cross-attention weights in the image and text UNets with image-text pairs,
Freeze the text-UNet’s weights, and train the audio UNet’s weights with text-audio pairs,
Freeze the audio UNet’s weights, and train the video UNet’s weights with video-audio pairs.
Because they froze one of the UNet’s weights after each step, these weights were “bridged” by the text UNet, which was the first one to be frozen. The researchers call this process Latent Alignment; the figure below shows step 3, video-audio pair training. The faded-out components are the ones that aren’t active during video-audio training: text components and the audio encoder.

Once they’d trained all the cross-attention weights, the researchers could generate any combination of these modalities! For example, the image below depicts [text+image]-to-[video+audio]:

Thanks to the aligned UNets, CoDi generates temporally aligned video and audio, like in the “fireworks in the sky” generated video/audio below, where the visual firework explosion is synchronized with the sound!
While CoDi is quite an impressive model, I think the biggest contribution of this paper is that it shows that it’s feasible to train AIs that link different kinds of data together, even if there isn’t any training data linking them. This idea will become more and more important as we discover new types of data that we can apply AIs to, or for generating synthetic datasets that link modalities that don’t usually occur together (like images and audio).
If the fireworks video above isn’t displaying for you, you can view it directly by clicking this link.