
One-shot text-to-image face accuracy: Into the PhotoVerse
Paper: PhotoVerse: Tuning-Free Image Customization with Text-to-Image Diffusion Models

Summary by Adrian Wilkins-Caruana
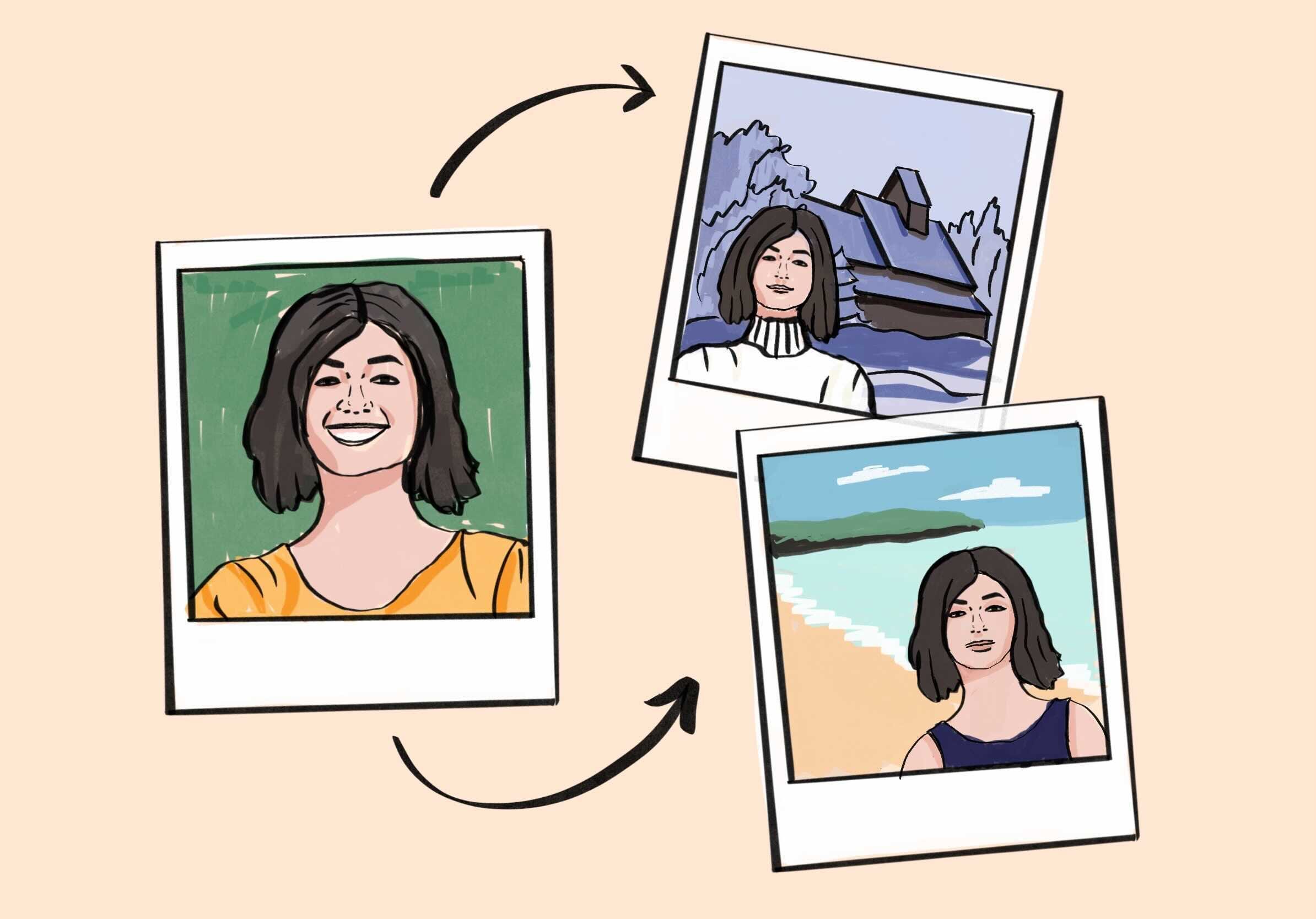
Have you ever wanted to see yourself as a superhero, a historical figure, or even in a whimsical fantasy setting? With personalized text-to-image tools, turning such dreams into digital realities is closer than ever — but there's a catch! Current methods can take ages to generate personalized images, require a whole gallery of your photos, and often struggle to keep ”you” looking like, well, you. A nifty new tool called PhotoVerse could be the answer to these image-generation woes. It can generate new photos of a subject from a single photo using a text-specified style in ~5 seconds, and it can do this while ensuring that things like the subject's eye and hair color stay the same. Before diving into this paper, let’s have a look at five different style renditions of Anya Taylor-Joy:

The creators of PhotoVerse set out to make neural image customization more useful and practical. Toward this goal, they didn’t reinvent the wheel — they used the Stable Diffusion model for image generation, and the joint image-text CLIP embeddings for encoding images and text. They also used an established concept called “pseudo-words,” which uses an image encoder to generate word-like tokens, represented in prompts as S*; these tokens describe an input image and can be used in prompts. For example, in the images above, S* represents the original photo of Anya Taylor-Joy. The key to PhotoVerse is combining all of these pieces, plus some additional tricks, into a single model.
The first trick is to pre-process the provided image to remove the background and any other superfluous information that could confuse the diffusion model. For example, in the architecture diagram below, the background and neck are removed from the photo of Taylor Swift. The next key component of PhotoVerse is an architecture in which the diffusion model receives not only text prompt information (p in the diagram), but also a vector that captures direct visual data from the input image (f for “facial info” in the diagram). The authors call this a dual-branch architecture. The text branch isn’t novel (it’s a core part of Stable Diffusion), but the image branch is: It helps the diffusion process maintain some of the visual features of the provided image. These two branches are shown in the figure below, with the image branch on the left and the text branch on the right.

In the diagram, the little switch with the f and p are where the visual and textual features from each branch are combined. To learn how to use this combined info, PhotoVerse needs to fine-tune parts of the diffusion model. Instead of fine-tuning the entire diffusion model (which would be quite slow), the researchers only fine-tuned its cross-attention modules, which are the parameters that control how much influence the image and text information have on the generated image. They used a random parameter to explore and learn the best relative weights to put on the information coming from both the f (face) and p (prompt) dual branches.
They fine-tuned their customized version of Stable Diffusion using the standard reconstruction loss, plus an additional “facial ID” error term that measures the similarity (i.e., cosine similarity) between the provided image and a denoised image with the prompt “A photo of S*.” This aspect of the loss function (the added facial ID), along with the new input from the visual encoder, work together to create output images that are more clearly recognizable as the person in the provided image.
The authors demonstrate the benefit of the PhotoVerse approach qualitatively, as you can see below. The comparison models (E4T and ProFusion) can both generate a rendition of the input image using the provided prompt but, in each case, the PhotoVerse result (rightmost column) generates a rendition that does a far better job capturing the facial features of the person in the input image. The authors also show that the PhotoVerse configuration diagrammed above is the best at generating images that look like the person in the input image (compared to alternative PhotoVerse configurations). They calculate this using the same “facial ID” used in the loss function.
Unfortunately, the authors don't use the “facial ID” method to quantify that their method preserves the facial features better than the baselines. Regardless, I think the PhotoVerse images are clearly superior, and fit for a variety of applications such as generating profile pictures, or helping artists generate creative renditions of characters or people.
