
"My voice is my passport:" AI speaks in your voice without training
Paper: Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale

Summary by Adrian Wilkins-Caruana
What exactly is it about some machine learning models that distinguishes exciting research projects from ones that can have a significant impact on our lives? Well, I’m not exactly sure, but it could be zero-shot learning (a.k.a. out-of-context learning). Zero-shot learning is the ability of models like Stable Diffusion to generate images of whatever you can imagine, or of GPT-4 to answer questions it’s never been asked before.
This new paper from Meta AI might be the “zero-shot moment” for audio models. Their new model, called Voicebox, is a multilingual audio model for generating speech, and is the new state-of-the-art model for many text-to-speech (TTS) tasks. The keys to Voicebox’s ability to generalize are its speech-infilling training task, a vast training dataset, and its unique architecture.

They trained Voicebox to predict missing speech given the speech that comes before and after the missing segment, and a complete text transcription of the speech. This is called a text-guided speech infilling task. The training data consists of 60k hours of English audiobooks and 50k hours of audiobooks in six other languages. Like other popular TTS models, the text is a phonemic representation of the speech, and the input audio is represented as a mel spectrogram, which is an image representing the temporal samples (x-axis), frequency (y-axis), and magnitude (pixel value) of the speech. The Voicebox model consists of two parts:
An audio model that predicts the frequency magnitudes at a specific point in time given the surrounding audio context and the phoneme at that point in time
A duration model that predicts the speech duration of each of the provided phonemes
Before Voicebox, the state-of-the-art TTS model was a system called VALL-E, which works kind of like a transformer in an LLM: It predicts future audio “tokens” based on past ones by conditioning on a text prompt. But, unlike VALL-E, Voicebox is a continuous normalizing flow (CNF) model. If you haven’t heard of CNFs before, that’s okay — for this article, you can think of them as a kind of diffusion model. CNFs are trained using a recently proposed technique called flow-matching, which models the transformation from a simple distribution (like a Gaussian) to a complex data distribution (like images or audio).
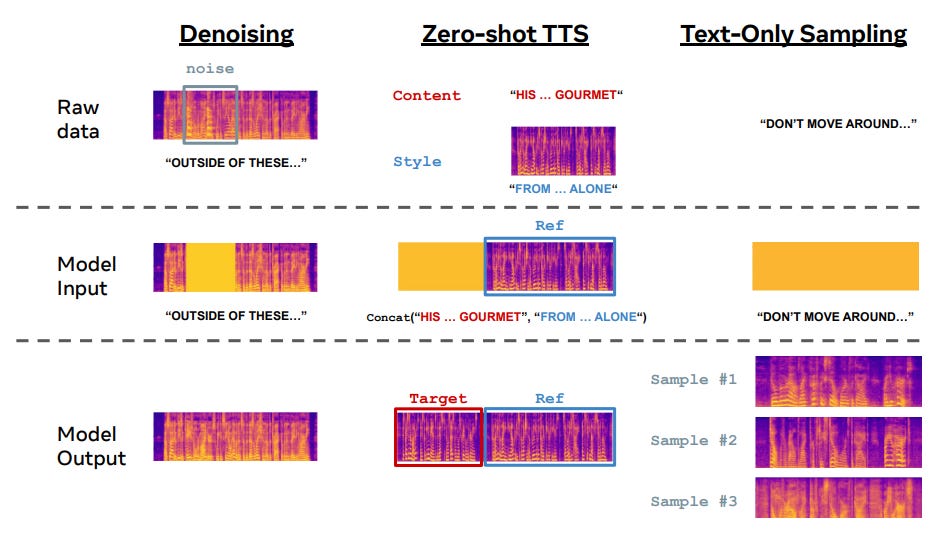
The figure below shows three kinds of generalization that Voicebox can achieve after training with the speech-infilling task:
Given a noisy audio sample and the text transcription, it can denoise the audio.
Given some text and partial audio for the text, it can fill in the missing audio.
It can generate audio from text, although the style may vary across samples (as you’d expect).
The researchers compared Voicebox to VALL-E for monolingual (English) zero-shot TTS in a transcribed TTS dataset (Librispeech test-clean). Compared to VALL-E, Voicebox reduced the previous state-of-the-art word error rate (WER) from 5.9% to 1.9% and increased the audio similarity from 0.580 to 0.681, where 1 is the maximum value for structural similarity.
On the multilingual front, the previous state-of-the-art model, YourTTS, can speak English, French, and Portuguese, while Voicebox can speak these languages and German, Spanish, and Polish. Compared to YourTTS, Voicebox reduced the average WER from 10.9% to 5.2% and improved audio similarity from 0.335 to 0.481. Also, the multilingual Voicebox model doesn’t need multilingual utterances from the same speaker, which means that it can generate speech in a speaker’s non-native language.
Voicebox can also infill speech of any length, and outperforms the existing state-of-the-art model (A3T) by 8.8% on WER, 0.450 on similarity, and is preferred by human evaluators when judging the quality and intelligibility of the speech. A multilingual TTS model like Voicebox can be used in all sorts of settings, such as call-centers, announcements on train platforms, or even for dubbing movies and TV shows in other languages in the same voice as the actor. With its improvements over existing models, perhaps Voicebox will become the GPT-4 of TTS models!