
Measuring a model's understanding — starting with path-finding
[Paper: Evaluating the World Model Implicit in a Generative Model]

Summary by Oreolorun Olu-Ipinlaye
Machine learning is all about finding a function that fits a dataset and works well on new, unseen data. Take a basic linear regression task: You’ve got some feature x and you want to predict a target y. By training a model, you end up with a function y = mx. In very simple terms, we could say we’ve taught a model y = mx. Generative sequence models aren’t as easy to picture but they work similarly. Recent research has shown that they learn what’s called a world model, which lets them produce meaningful responses — and maybe even reason. But how do we figure out how good these world models are? That’s the question today’s paper looks to answer.

So, what exactly is a "world model?" The authors explain it as a way to represent a set of states and the rules that determine how those states change. In simpler terms, a world model is how a generative sequence model understands and applies those rules. This paper points out a problem with how we currently evaluate these models. Right now, we mostly treat them as fancy next-word predictors, checking how well they guess the next token in a sequence. But the authors argue there’s a better way: Instead of focusing on the immediate next token, we should look further down the line. Those later tokens are harder to predict, so evaluating them would give us a clearer picture of how good the model’s world understanding really is.
To make this clearer, the authors use the game Connect 4 as an analogy. At the start of the game, when the board is empty, it’s pretty easy for a model to predict a valid move — disks can go anywhere. But as the board fills up and valid moves become fewer, the model is more likely to make mistakes and predict invalid ones. This shows that a model with a stronger world model will do better as the game progresses and the sequence gets more challenging. The takeaway? Instead of focusing on individual predictions, we should evaluate models on how well they handle longer, more complex sequences.
The researchers referenced the Myhill-Nerode theorem to create two metrics. The theorem basically says that if two sequences lead to the same state, their continuations should be the same; but if they lead to different states, their continuations should differ. Here’s how they turned that idea into metrics:
Sequence compression: Checks whether the model predicts the same continuation for two sequences that end in the same state.
Sequence distinction: Checks whether the model predicts different valid continuations for sequences that end in distinct states.
To test their metrics, the researchers trained transformer models on a dataset of New York City taxi rides, turning each trip into sequences of turn-by-turn directions, culminating in over 120M sequences. The figure below shows what these sequences look like. The numerical figures represent start and stop nodes, respectively (each intersection is taken as a node and assigned a unique index) and the letters represent cardinal directions. They trained two models, one with 89M parameters and one with 1.5B parameters. Impressively, these models could predict valid routes between intersections and often even find the shortest path to a given destination. But deeper analysis revealed that their internal "world models"—representations of NYC’s street map—were incoherent.
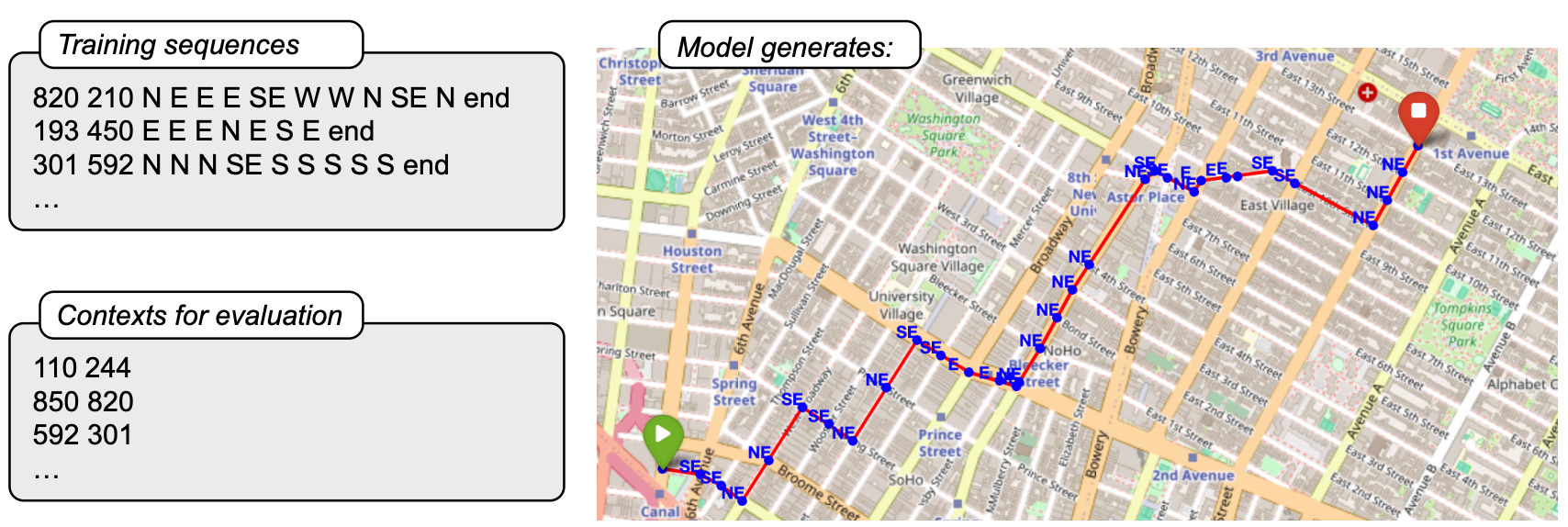
Here’s how the team put their metrics to the test. For sequence compression, they picked a specific intersection (a “state”) and found two different routes leading to it. Then, they checked whether the model gave the same next turn for both routes. If it did, that meant the model understood that these were just two paths converging on the same destination. For sequence distinction, they looked at two different intersections and their respective routes. The goal? See whether the model’s predictions made sense for each intersection — in other words, were the turns even valid? Did they line up with the real-world map? The results were mixed: The models were poor on sequence compression, failing to recognize when routes led to the same place. But for sequence distinction, the 1.5B-parameter model did pretty well, while the 89M-parameter model struggled.
You might be thinking, "If these models can find the shortest path so accurately, why do these metrics even matter? Does having a solid world model really make a difference?" The researchers found out that it does. When the researchers threw in detours, the models struggled to reroute to the destination. Basically, when things get messy, models with weak world models perform poorly. To make this clearer, the team even reconstructed what the transformer’s world model thought the map looked like. It looks really different from the actual map:

This paper feels important because it highlights that just because transformers perform well on specific tasks doesn’t mean they’ve actually nailed down a solid world model — even if older evaluation metrics made it seem like they had. And that’s a problem because if a world model isn’t strong enough, the system is way more likely to stumble when you throw unexpected changes its way.