
Making LLMs scalable by replacing weights with learnable tokens
[Paper: Tokenformer: Rethinking Transformer Scaling with Tokenized Model Parameters]

Summary by Adrian Wilkins-Caruana
Has it ever occurred to you that, somewhere in OpenAI’s ranks, there’s an engineer who pressed a button that triggered what in all likelihood amounted to GPT-4’s multi-million dollar training process? As an engineer myself, I’m sweating just thinking about it. To make an LLM larger, researchers typically increase the number of layers and tokens, as well as the length of the model’s weight vectors. Unsatisfied with this trio of variables, Wang et al. have designed a new LLM approach that offers much cheaper training. The crux of their idea is that the model’s parameters are tokens, just like its input! They call their approach Tokenformer.

Before diving into the details, it’s helpful to first try to understand why the researchers might have explored this idea in the first place. In a regular transformer, the computation can be split into categories: one where tokens interact with static model parameters (e.g., in linear projections of queries, keys, and values, as well as the post-attention linear projections), and another where tokens interact with themselves (e.g., self-attention). The researchers noticed that the token-parameter interactions accounted for the lion’s share of computation, so it’s easy to imagine that they might have discovered Tokenformer by trying to make a model that’s more reliant on token-token interactions. In fact, Tokenformer relies entirely on token-token interactions.
Now let’s see how Tokenformer works. Because it only uses token-token interactions, all the linear projections need to be replaced with attention layers, which the researchers call Pattention layers (named from the phrase “token-parameter attention”); they’re kind of like cross-attention layers. Actually, Tokenformer’s main attention layer consists of several Pattention modules, and a vanilla self-attention module. As tokens come into the main attention module, Tokenformer processes three copies of them in parallel in separate Pattention layers. Each Pattention layer combines the inputs with two sets of parameter tokens, which the researchers call key and value parameter tokens. The outputs of these three copies form the queries, keys, and values for the regular token-token attention module. Tokenformer then processes the post-attention projections using Pattention layers, too. Tokenformer’s attention layer is depicted below on the left, and the Pattention layer is on the upper-right.

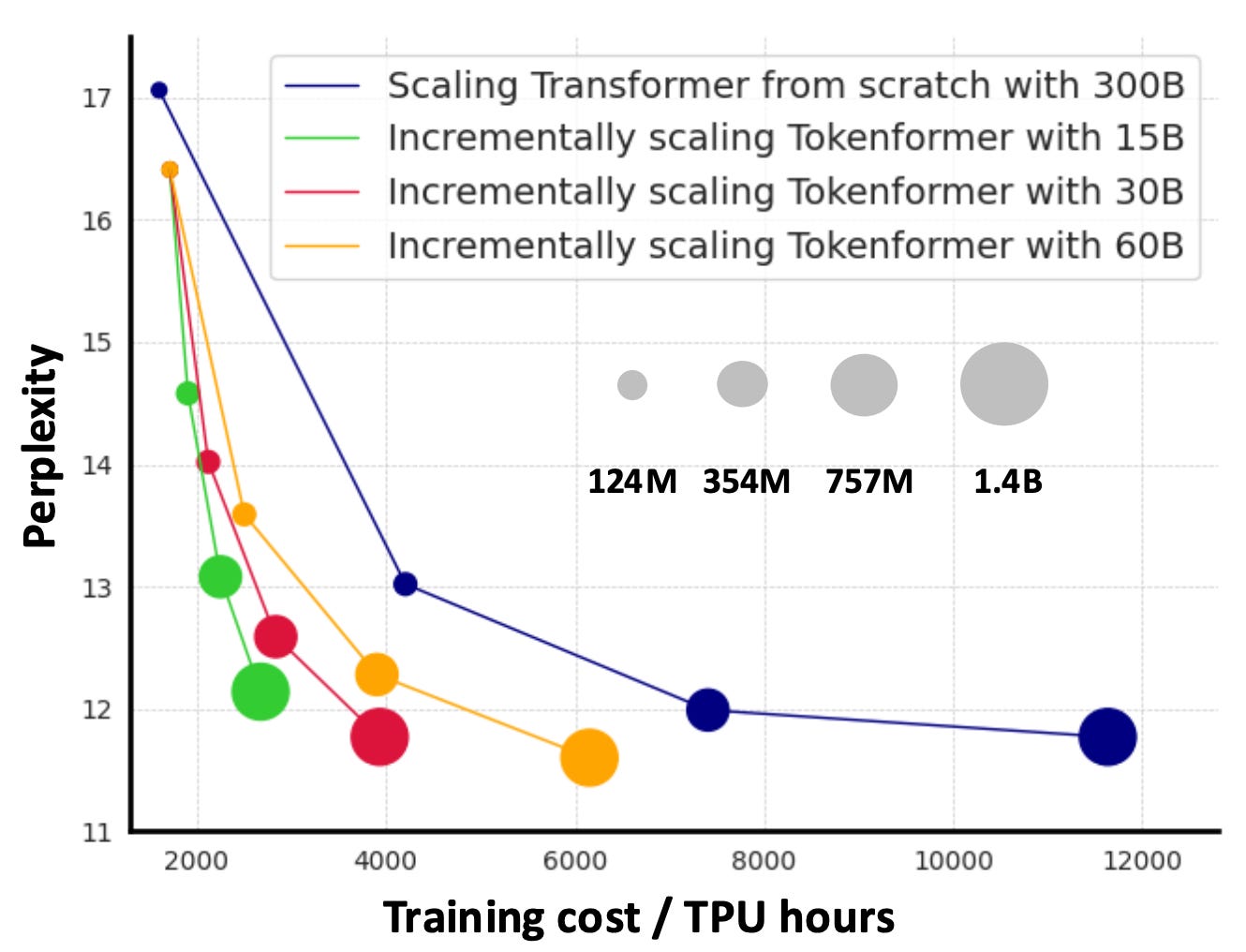
By adopting this strange configuration, Tokenformer gains a new ability to scale itself by progressively adding more parameter tokens during training. The lower-right quadrant of the figure above shows this process. To do this, Tokenformer first undergoes some initial training with a modest amount of parameter tokens. Then, the researchers duplicated each sequence of parameter tokens, concatenating onto the end of the existing parameter token sequence before they resumed training. This process can be repeated several times to scale up further, as shown below. We can see that even with fewer overall parameters, Tokenformer models typically are better at predicting the next word (lower perplexity) with less training time than a regular transformer.
You might be wondering, “If we can use parameters as tokens, then what’s the difference between tokens and parameters in the first place?” There’s several ways to look at that question. One is that, after training, tokens can change but parameters typically stay the same. By this definition, the parameter tokens are still really just parameters, since they don’t change. Another way to look at it is that the length of a token’s vector is typically smaller than the length of a parameter’s vector. So parameter tokens are more like tokens in this respect, since they have the same dimensionality as regular tokens. Personally, I think the distinction between parameters and tokens is kind of arbitrary, and that it might be better to call these parameter tokens “token-like parameters” because they’re more like parameters than tokens. But that’s just my opinion.
Another thing you might be wondering is why this approach even works. The key change is that Tokenformer swaps linear projections (i.e., y=σ(xA^T+b), where A is a weight vector, b is a bias vector, and σ is, counterintuitively, a non-linearity) for Pattention layers. But, as it so happens, Pattention layers look an awful-lot like linear projections: Input tokens are combined with keys in the same way, while the value parameter tokens are like the bias (not exactly, though). There’s even a non-linearity too, though it’s not pictured in the first figure above. So, it’s really not that surprising that something like Tokenformer works.
The researchers tested Tokenformer on both vision- and language-modeling tasks, and their results indicate that the method works well in practice, but further research will need to be done to determine whether their approach has some subtle weaknesses or if it can scale up to the size of foundation models. I’ve been reading about and using transformers for years at this point, but it’s always a delight to learn about the new ways that researchers are modifying the architecture to solve new problems or address existing challenges. The idea of Tokenformer — using parameters for tokens — seems like an obvious thing to try but, as always with matters of familiarity, it’s not one that I or any other AI researchers have shown the viability of before.