
LLMs that never forget
[Paper: Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention]

Summary by Adrian Wilkins-Caruana
Just a few weeks ago, we covered some papers from Hao Liu — a PhD student at UC Berkeley — that describe how to modify an LLM’s architecture so that it can process million-token sequences. In the article, I speculated that these techniques might be how Gemini 1.5 Pro — a new LLM from Google — achieved its long-context processing abilities. Well, just a few weeks ago, Google released a research paper of their own describing how an LLM can process infinite-length contexts using an interesting idea called compressive memory. The authors call their technique Infini-attention.

The figure below shows how the “attention” part of Infini-attention works. It begins by chunking the input sequence into segments, and then computing attention on a segment-by-segment basis. The green blocks represent a “memory” that’s updated with information from each segment that is then accessible by all subsequent segments.
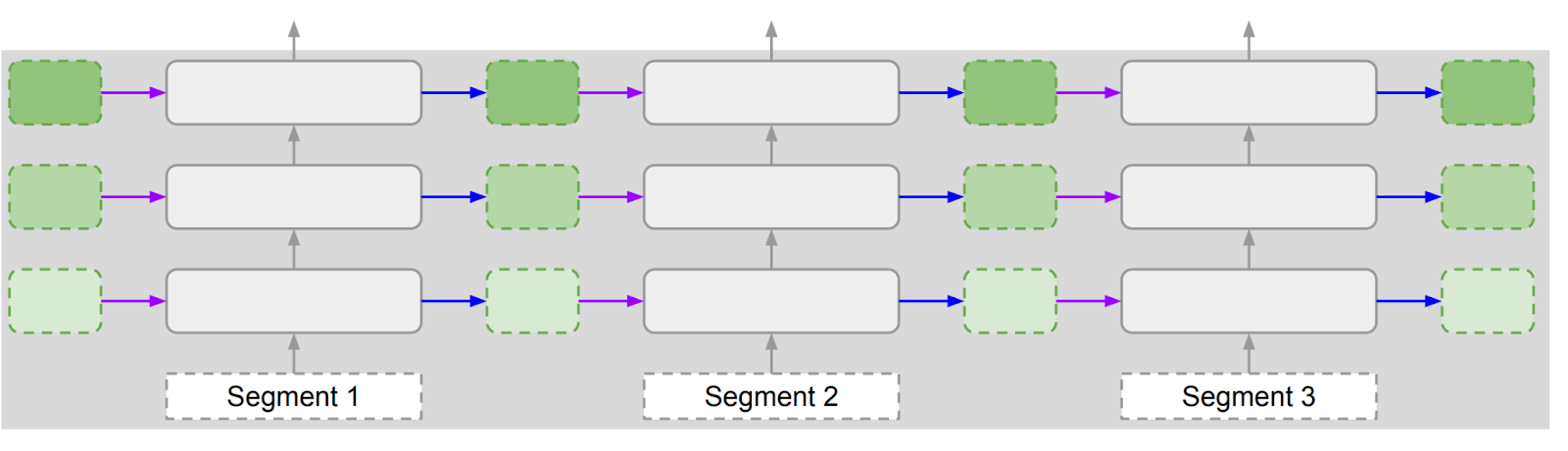
As you can see in the next figure, Infini-attention is actually a combination of two types of attention: vanilla attention (purple) and compressive memory plus linear attention (green). Due to the segmentation, the purple vanilla-attention blocks compute the interactions between the queries, keys, and vectors of within-segment tokens only (Qs and {KV}s). The compressive memory, on the other hand, remembers the keys and values from previous segments {KV}s-1. The memory is built up iteratively, starting with the first segment. So, by querying this memory with the current queries Qs, the output projection from each segment can still be aware of the keys and values of all tokens in all preceding segments.

These two kinds of attention are similar but differ slightly. Here’s how the linear attention (green) and vanilla attention (purple) are computed:

There are two things to note: First, each attention uses a different non-linearity: ELU+1 (nicknamed σ) for linear attention, and softmax for vanilla attention. Second, the vanilla attention requires quadratic space to compute the softmax, whereas the linear attention can be computed linearly, i.e., without quadratic space. I’ll discuss the implications of these differences in a moment.
The compressive memory is a special kind of memory called an associative memory. At its most basic level, this memory is just a matrix of values that changes every time it’s updated with new information — which, in the case of Infini-attention, are the keys and values from segments. The memory’s contents for the ith segment can be written as follows:

The subscripts on the K’s and V’s indicate which segment they’re from. The cool thing about this memory is that we can retrieve any given value v as long as we have the corresponding key k, where v and k are row vectors that have been previously stored in the memory. If we pretend that all of the K’s and V’s in the above equation have only a single row, and if we ignore the non-linearities for a moment, then we can retrieve V_2 from the memory using K_2 like this:

The way I see it, structuring the memory this way has three main benefits: First, the size of the memory stays the same no matter how many segment’s worth of keys and values are stored in it — it’s a d_k × d_v matrix. Second, the form of M is ready to be queried as-is: ignoring non-linearities, QM is equivalent to the definition of A_{linear}.
The third cool thing about this memory is that storing keys/values can be made slightly more efficient by modifying the storage process. The regular way to store new keys and values is to simply add them to the previous memory state M_{i-1}, like this:

But with Infini-attention, we can retrieve the existing value from the memory and only update the memory with the difference between the value that was stored previously, like this:
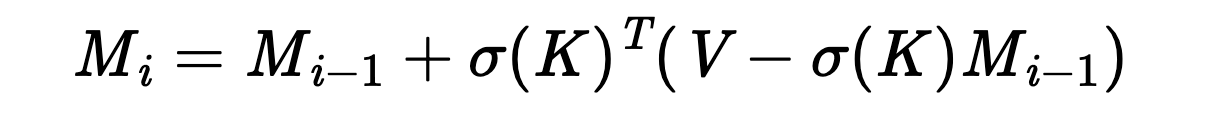
The authors call this a “linear + delta” memory update, and it helps stop the memory from getting cluttered with too many values.
The concept of combining compressive memory with linear attention is definitely neat. But it left me thinking: If the compressive memory with linear attention can cover the entire context length, then what’s the point of continuing to use the regular attention?
The reason they did so is that these two types of “attention” aren’t really equivalent. The linear attention idea isn’t new — it’s commonly used in compute-constrained contexts or when large contexts are necessary — but it’s not as effective as vanilla attention. That’s why vanilla attention hasn’t gone away; for example, the best open-source LLMs like Llama 3 use vanilla attention. So, I guess Infini-attention is trying to have the best of both worlds: It uses vanilla attention for short snippets of a long context, and linear attention to cover the rest of the context. Ultimately, though, I suspect Infini-attention probably isn’t going to work as well as full-context vanilla attention.
In the rest of the paper, the Google researchers present some experimental results that show that Infini-attention works really well at the “passkey task” — which is essentially a needle-in-a-haystack challenge — after the model has been fine-tuned a little bit on that task. They also show that the Infini-attention method works better than other long-context techniques, and that the “linear + delta” approach works slightly better than the linear-only approach. I was hoping that this paper was going to reveal a silver bullet for long-context attention, but in reality it seems like another band-aid approach to me. But it’s great to see that people are coming up with new and — in the case of the associative-memory approach — very clever techniques.