
How Meta built a model that really can Segment Anything
Spoiler: They used AI.

The phrase “the singularity” refers to a prophecy in which technological growth becomes uncontrolled and irreversible. I’m uncertain about this concept because I think of technological growth as both useful and difficult to achieve. To me, the idea of the singularity is akin to my bank account balance experiencing uncontrolled and irreversible growth. It’s both good — and a bit unlikely.
Whether or not the singularity is something we later see as a historical event, something very real is changing in the way we train models. Specifically, the output of previously- or partially-trained models has become so useful that the output from one can be used whole-cloth — or with some human-expert adjustment — as training data for better models. Consider the next image, which is not a deliberate piece of colorful art, but rather shows an image from a grocery store in which every single item has been segmented individually, down to the pixel:

This is just one of many annotated training images used to create Meta’s impressive Segment Anything model. Can you imagine a human taking the time to create this? And then create thousands more like it? It’s not practical; and it didn’t happen. The researchers behind Segment Anything pioneered techniques to bootstrap their own training data with earlier models. This is a great model, both because it’s a clear step forward, and because it’s a well-executed example of how AI can train AI.
Paper: Segment Anything
Summary by Adrian Wilkins-Caruana
Meta has released Segment Anything, a paradigm-shifting image segmentation model. Image segmentation is a quintessential computer vision task, where an algorithm tries to identify a boundary where one thing ends and another begins. If you’ve ever used Adobe Photoshop, you might be familiar with the Magic Wand tool, which lets you quickly select a region in an image that has mostly uniform brightness. AI-based segmentation methods have rapidly improved over the past decade, allowing automated segmentation of complex objects. These methods are typically trained on lots of hand-labeled masks of objects, such as people, vehicles, or roads. But Segment Anything doesn’t need to collect expensive hand-labeled masks — it can segment using prompts!
Here’s an image that shows how the Photoshop Magic Wand tool works (left) and what some masks from an image segmentation neural network might look like (right).


Generative language models like GPT-3 have been shown to be “zero-shot” problem solvers, which means they can solve problems they weren’t specifically trained to solve. This is the idea behind Segment Anything: given a prompt about what to segment and an image on which to perform the segmentation, generate a mask. How is this possible? Well, pretend you’ve never seen “food” in your life, but on many occasions you’ve read about how this mysterious “food” thing usually sits atop a plate. Now, if you were asked to identify the “food” in an image, you could reasonably assume that it’s that strange-looking stuff sitting on the plate, and you’d know that the “food” ends where the plate begins. That’s zero-shot generalization, but for image segmentation.
And Segment Anything isn’t limited to prompts that are text describing which object to segment. It can segment with spatial prompts too, such as a point in an image, a box, or even a “blob.” For example, the cat in the image below can be segmented using any of these kinds of prompts. The training examples used to train the main Segment Anything model consist of a paired spatial-segmentation prompt (i.e., points, box, or blob) and image, and a “valid mask,” a mask that segments which pixels in the image are the thing in the prompt. In contrast, traditional segmentation models use just an image and a valid mask (with no prompt).

To train Segment Anything, the researchers defined a new learning task that’s inspired by how LLMs are trained. When an LLM tries to predict the next token in a phrase like “Today, I went to the ___”, it knows many plausible tokens that could come next, like “shops” or “post office.” The Segment Anything task is similar: The generated mask is scored according to how reasonable it is. In fact, it actually generates many masks and scores that correspond to how confident the model is that a generated mask segments the thing in the prompt. This is really important for a foundation-scale segmentation model, especially because the segmentation prompts are often ambiguous. The figure below shows how Segment Anything uses some text, a box, some points, or a mask (blob) to generate many valid masks and scores.
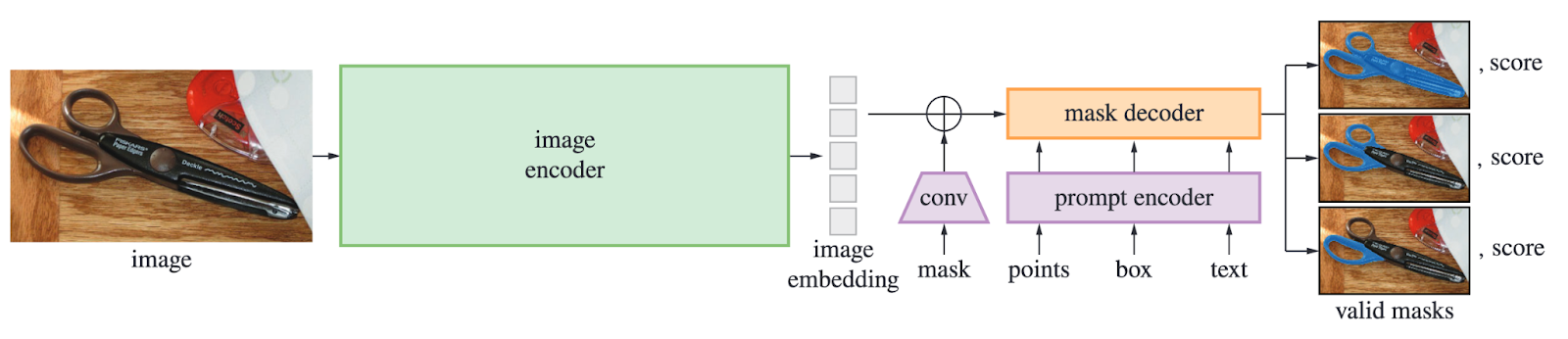
If a foundation LLM is trained on the internet, then what is a foundation segmentation model trained on? Well, the Segment Anything dataset consists of 11M images and 1B+ masks (i.e., ~90 masks per image), and was curated in several annotation stages. In stage 1, people manually annotated masks in the images. Using a model trained on these annotations, stage 2 was semi-automated and aimed to improve mask diversity: given an image-mask pair, annotators further labeled some of the less obvious things in the image (this technique encouraged the creation of less obvious masks). Finally, in stage 3, after training a model on the more diverse masks, the model automatically generated even more masks for each image via a 32x32 grid of point-wise prompts, thus creating more masks for things located at each of the points. Here are some examples of images and masks from the dataset.

Even though Segment Anything is trained with only spatial prompts, it wasn’t complicated to add text-based prompting to its repertoire. To do this, the researchers used the OpenAI CLIP model to extract “embeddings” for each mask, which are numerical representations of the thing being masked. CLIP is an aligned image-text embedding model, meaning that it generates similar embeddings for an image of food as it would for the text “food.” So, when it comes time to segment something using a text prompt, Segment Anything knows what that thing looks like based on the CLIP embedding of the text prompt, since it’s likely seen those embeddings during training, except those embeddings were generated from the images and masks in the training set.
Promptable vision models will enable creative solutions to vision problems, like how ChatGPT can help you write emails and plan holidays. Perhaps it won’t be long before we can generate “an image of a hand with five fingers,” a problem Stable Diffusion seems to struggle with…


