


Generating optical illusions
Paper: Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models

Summary by Adrian Wilkins-Caruana

What do you see in the image below: a duck or a rabbit?

You’ve no doubt encountered this illusion before. When I was a child, I could only see the duck. That was, until I realized I could see the rabbit if I turned my head 90 degrees counterclockwise. While the image itself is interesting, I’m more intrigued by how you’d create such an illusion in the first place. I’m not very artistically inclined, but I imagine it’s quite difficult. How do you ensure that the image looks just as much like a duck as a rabbit, and not more of one than the other? It’s as if the image has a kind of symmetry — not a geometric symmetry, but a conceptual or semantic symmetry.
Now, while I’m not very artistic, my brain does appreciate computer science and mathematics. And, luckily for me (and hopefully for you too), today’s paper has given me an insight into how an image like this works. As the authors describe it, a visual anagram is an image that changes its appearance to an observer after a transformation, such as a flip or rotation. Like a regular anagram, it’s a way to rearrange the parts of something — such as the letters in a word or parts of an image — into two valid forms. The paper describes how diffusion models, like Stable Diffusion, can be made to generate these visual anagrams and, in doing so, provides some insight into the properties of such images.
To whet your appetite, below are some examples of visual anagrams generated by the method from this paper. These are examples of polymorphism, where the parts of the image, which in this case are jigsaw pieces, can be rearranged into two different valid images. As we’ll discuss in a minute, polymorphism isn’t the only type of perspective or image change: There are also flips, rotations (of the full image or a subset), skews, and color negations (such as flipping black for white).

The method from this paper is conceptually quite simple. You may already know that diffusion models generate images through a series of denoising steps. When an image is partially denoised, the model estimates how much of the image is signal (meaningful data) and how much is noise (random data). Then the model subtracts the noise estimate from the image and continues to the next step. To make a diffusion model generate a visual anagram, the noise estimation is done on two versions of the image, where each version has had some kind of transformation applied (e.g., one is flipped). The authors call this process parallel denoising, and it’s shown in the figure below, where x_t is the partially denoised image, and v_1=id and v_2=flip are the two transformations.
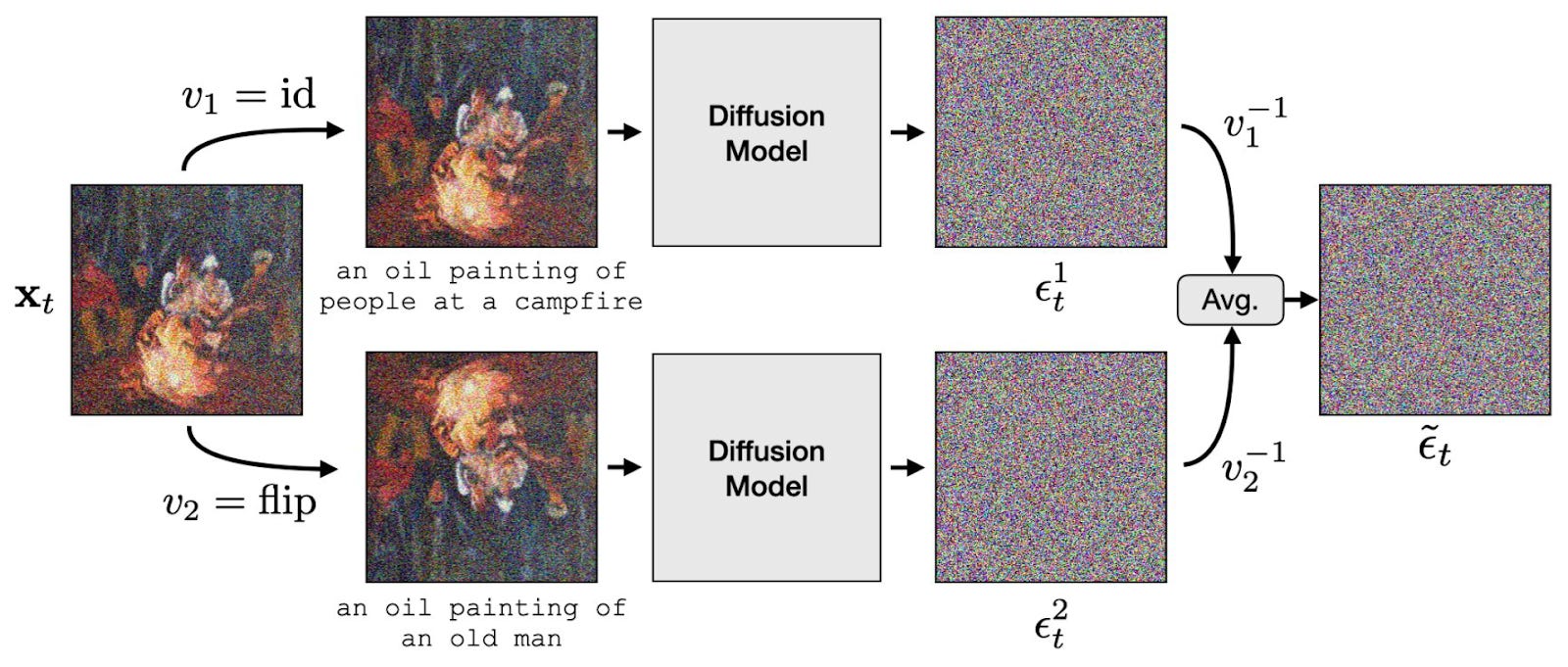
The term id means “identity,” which is a fancy way of saying “don’t do any transforming,” and flip means “reflect the image across a horizontal line in the middle of the image.” When the diffusion model estimates the noise in each transformation, it’s also given text prompts, one for each perspective — this is how the image can represent different things under different transformations. Now, even though it’s estimating the noise twice, we still want only one final image as output. So the model combines the two noise estimates by undoing the transformations (for example, unflipping the flipped version) and taking the average of the results.
There are some limitations on what constitutes a “valid” transformation, which stem from the technical details of how diffusion works. For example, diffusion models operate on images that are a combination of signal and noise. The combination can be weighted, but ultimately it must be a linear combination of the two. In this equation, x_t denotes the image at time t (the algorithm iterates in time steps denoted by t) and this is decomposed into a linear combination of signal and noise images:

This means that, if we change the image using a transformation v, then it must be a linear transformation, which the authors represent as a matrix A:

In this way, the image that results from the transformation will still be a linear combination of signal and noise:

In addition to the linear requirement, diffusion models also expect the noise to be sampled from a specific probability distribution. This means that the transformed noise, Aϵ, also has to follow the same distribution.
Among the valid transformations that the authors considered are: spatial rotations and reflections; skewing; permutations, such as rearrangements of image patches or jigsaw pieces; and color inversion. The authors don’t say what kind of transformations these requirements rule out, but one example I can think of is a complex color-dependent transformation.
One cool thing about this parallel diffusion approach is that it can be extended to support more than two image perspectives at a time. The researchers did this by applying as many transformations as needed (one for each perspective/orientation/arrangement of the image) and combining them when averaging all the noise estimates during the diffusion process. For example, depending on which way you view the following image, you might see a rabbit, a teddy bear, a giraffe, or a bird. How many can you see? Personally, I can’t see the giraffe, but it’s still quite impressive.

There’s a lot more I’d like to say about how such a simple method can be so effective at creating illusions — such as how the model seems to know where it can add detail to images without adding confusion. For example, did you notice Marilyn Monroe’s face being outlined by plants in the jigsaw example above? I can’t even tell where the model hides Lincoln’s nose in the painting of the woman! I was also thinking that this could be a way to hide invisible messages in images using the permutation of patches technique. But this summary is getting quite long, so I’ll leave you with the web page associated with this paper, which has many more examples and some neat animations showing off different views of these versatile and virtuosic visual anagrams.