Diffusion with Transformers! 🖼🤖


Hello! And welcome to our first ever post about the awesome combo of Diffusion! and Transformers! This newsletter — Learn and Burn — is your regular update about the machine learning research that we at Unbox Research find most intriguing. Our goal is to take great papers and translate them into clear terms that get you quickly up to speed on why each paper is cool and how the authors achieved what they did.
I hope you like our first paper summary!
— Tyler & Team
Paper: Scalable Diffusion Models with Transformers
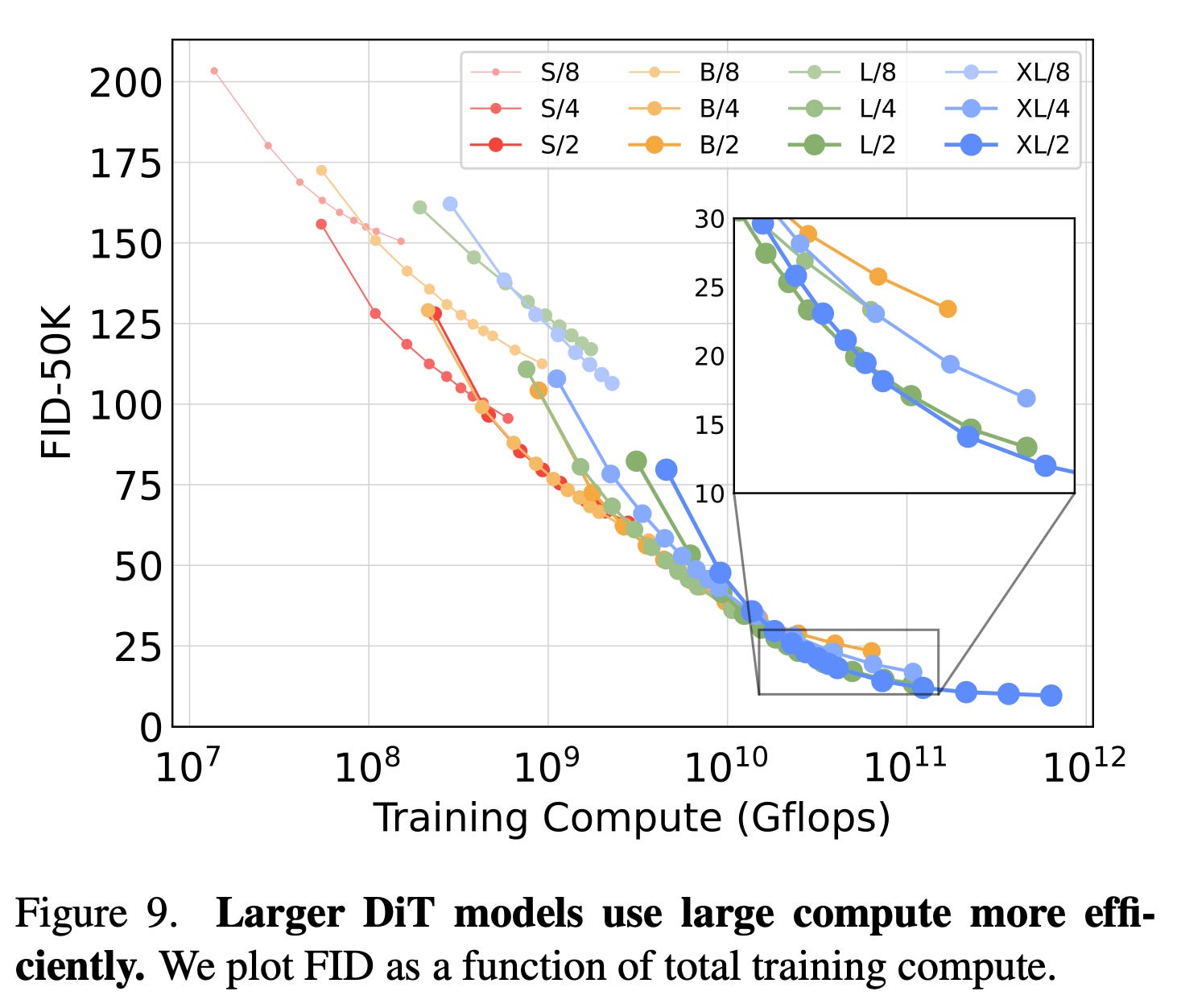
Diffusion models, which use the convolution-based u-net architecture, are now the de facto method for generating images. Peebles et al. have found that it's possible to train diffusion models that use the transformer architecture, and that such models have better scaling performance than their convolution-based counterparts.
To demonstrate the scaling properties of diffusion transformers (DiTs), Peebles et al. compared the network complexity of different DiT architectures to their image fidelity. They discovered that image fidelity correlates strongly with DiT size, and that large DiTs perform better than similar sized convolutional models.

Diffusion models can also scale by increasing the number of sampling steps. But this means of scaling doesn’t correlate with image fidelity in the same way as scaling the DiT’s size does. So Peebles et al. concluded that DiTs show promise in terms of better-than-convolution training efficiency.