
Defining and measuring AGI
Paper: Levels of AGI: Operationalizing Progress on the Path to AGI

Summary by Adrian Wilkins-Caruana
Many of the world’s top AI researchers are divided about when we’ll develop artificial general intelligence, or AGI, a term for AI that can learn any intellectual task humans can perform. Some researchers think AGI is imminent, while others think we are still decades away. These researchers often use anecdotal evidence about current AI capabilities to inform their positions. Wouldn’t it be better if we had a way to measure the AGI-ness of an AI model so that we didn’t have to rely on anecdotal arguments? Researchers from Google DeepMind have had exactly this idea – let’s see how it works.

First, let’s discuss how we measure general intelligence by looking at an analogous measurement: the autonomy of a self-driving car. This kind of autonomy is measured across six levels (from zero to five):
No automation
Driver assistance
Partial automation
Conditional automation
High automation
Full automation
The Google DeepMind researchers propose a similar six-level scale that they call Levels of AGI.
Unlike the self-driving autonomy scale, the Levels of AGI scale suggested in this paper actually has two axes: a performance axis spanning the six levels from no AI to superhuman, and a generality axis ranging from narrow for AI systems that can only do a small number of tasks to general that measures the breadth of tasks a single AI agent can perform. AlphaGo is an example of a narrow AI, since it can only play Go, while ChatGPT is an example of a general AI, since it can perform a wide array of tasks. This table from the paper succinctly outlines these two axes with more examples:
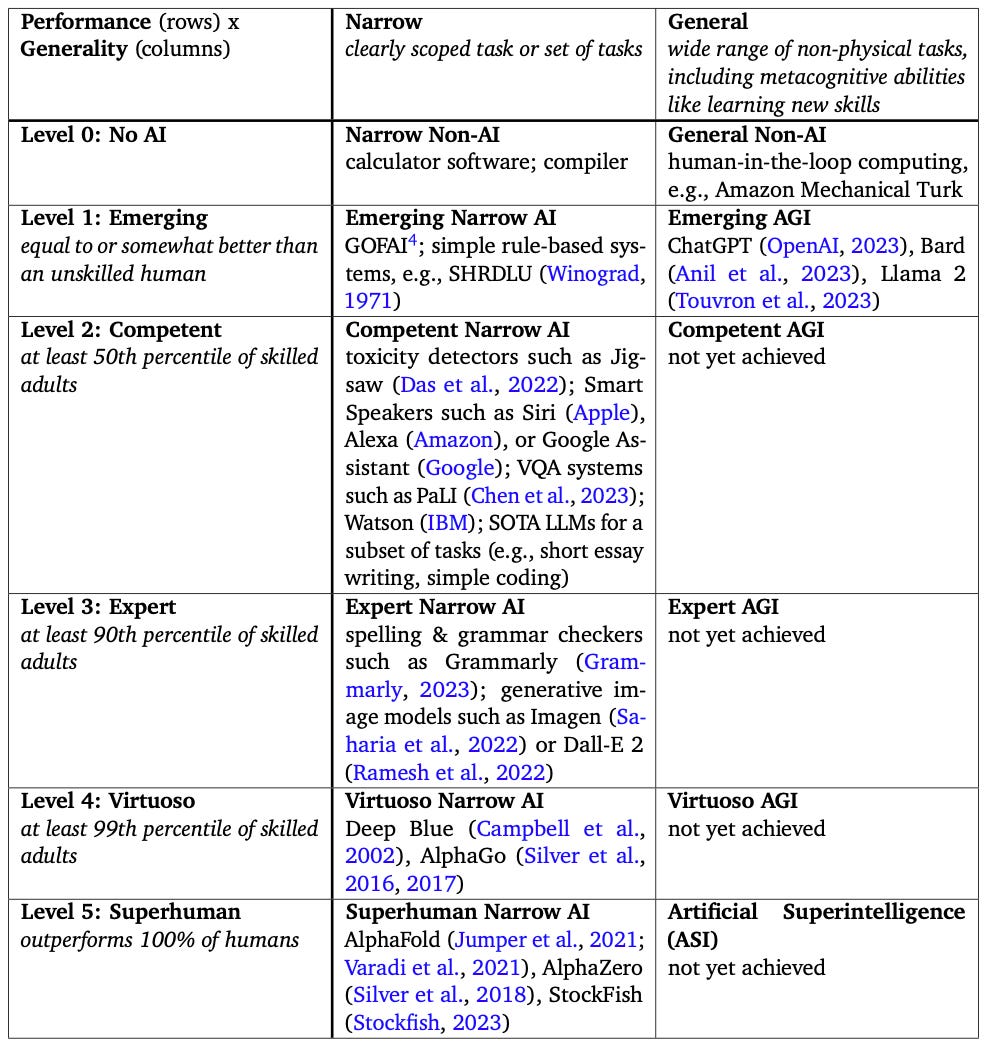
The first level of AGI, Level 0, is no AI. Being a zeroth level, this level captures the absence of intelligence in the AGI sense of the word. Examples of a narrow Level 0 AI are a digital calculator or code compiler, while an example of a general Level 0 AI is human-in-the-loop computing, such as Amazon’s Mechanical Turk.
The next level of AGI, Level 1, is emerging. It describes intelligence that is equal to or somewhat better than an unskilled human. Narrow Level 1 AI systems are those that make non-trivial decisions based on deterministic, pre-defined rules, while an example of a general, emergent AI is ChatGPT.
Level 2 describes competent AI: AI that is at least in the 50th percentile of skilled adults. You’re probably familiar with many competent, narrow AI systems, such as smart speakers like Siri and Alexa, IBM Watson, or domain-specific LLMs for essay or code writing. Level 2 AGI is the next frontier for AGI research, since we haven’t yet achieved any AGI that can perform many different tasks at the 50th percentile of skilled adults. For example, while ChatGPT can perform at or above this level on some tasks, it can’t do so on many of them, so it’s not a level 2 AGI.
Next are Level 3, expert; Level 4, virtuoso; and Level 5, superhuman. For an AI to reach these levels, it needs to perform in the 90th, 99th, and 100th percentiles of skilled adults, respectively. While AI models haven’t achieved general performance in these levels, there are AI models that can perform at these levels for narrow tasks, such as:
Level 3: Grammar checking (e.g., Grammarly) and image generation (Dall·E 2).
Level 4: Deep Blue (IBM’s chess playing system) and AlphaGo (Google DeepMind’s Go-playing system)
Level 5: AlphaFold, AlphaZero (Google DeepMind’s protein-folding and chess-playing systems) and StockFish (an open source chess-playing system).
The researchers considered nine different case studies (previous works that discuss definitions of AGI) to help guide them toward an appropriate, unified definition of AGI. Based on those case studies, they arrived at six principles as goals for any potential measurement of AGI. They suggest that a good definition of AGI should value:
capabilities over processes,
generality and performance,
cognitive and meta-cognitive (e.g. learning or knowing when to ask for help) abilities,
the potential impact of a system, as opposed to its current impact,
ecological validity (tasks that people value), and
it should focus on the path to AGI, not just a yes/no definition of an AGI endpoint.
One potential issue I see with this approach is in the ranking of AI models in percentiles of human capabilities. While games like chess and Go have winners and losers and formulas to rate players, we don’t have established ways of measuring less tangible things like the quality of an essay or the creativity of a work of art. There are ways, sure, but they are typically assessed manually by humans, not automatically like games or math problems. Being concrete and consistent about such measurements would be an important precursor to assessing the generality of an AI model.
William Thomson, a.k.a. Lord Kelvin (the namesake of the Kelvin temperature scale) once said, “If you can’t measure it, you can’t improve it.” This statement may be a simplification, but I do like the sentiment. A comparison without any tangible measurement is akin to a debate, which is how I feel about a lot of the other AGI discussions I read. With a way to measure AGI-ness such as the six levels proposed in today’s paper, we’re empowered to be more concrete when we consider questions like “What is the current state of AGI?” or “What are the shortcomings of state-of-the-art AGI systems?”
We’ll be taking a couple weeks off for the holidays. See you in 2024!
— Tyler & Team