
Computer, enhance image! 🖼 💫
Paper: Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild

Summary by Adrian Wilkins-Caruana
Diffusion models can generate images, so can they improve the quality of existing images, too? It seems plausible, right? What would actually be involved in doing this, and how hard would it be? In today’s paper, Fanghua Yu, Jinjin Gu, and their coauthors explore this exact question and take us through the challenges that they encountered along the way. To cut to the chase: Yes, it’s possible, but it’s not straightforward.

The first challenge is adapting a latent diffusion model, like SDXL, to a new task — image restoration. Latent diffusion models operate on images in a latent space, not in the x-y-rgb image space. This means you have to convert the low-quality, to-be-enhanced images into this latent space. But you can’t use the original encoder to encode these images because it wasn’t trained on low-quality images. This means that the encoder would perceive the high- and low-quality versions of the image as different, when in fact they’re semantically identical. So, the researchers’ first job was to retrain the encoder so that it’s invariant to (not affected by) image degradation. They did this by encoding high- and low-quality versions of images, and ensuring the latent space representations of the images were as similar as possible.

Once the low-quality image has been encoded, two processes start in parallel. The first process uses the vanilla SDXL model to decode the image. It then uses a multimodal LLM called LLaVA to analyze the image and generate a plain-text description of it. Interestingly, the researchers found that it’s beneficial to have both positive (e.g., sharp, high-fidelity) and negative text (e.g., blurry, grainy) descriptions of the generated images. The intuition is that, for SDXL to know that it should generate high-quality images, it should also understand what not to generate. Without this approach, sometimes some of the low-quality artifacts from the input images aren’t corrected.

The other parallel process generates the actual high-quality, restored image. To guide the SDXL towards generating a restored version of the low-quality image without having to retrain it, it’s conditioned on the text description from LLaVA (as mentioned above) and the low-quality image. They used a network called ControlNet to condition the diffusion on the image. ControlNet works by using a combination of the encoded low-quality image, the text prompt, and the partially diffused latent image.
The version of ControlNet in this paper consists of trimmed encoder copy blocks that influence the SDXL decoder to generate an image that’s similar to the low-quality input. These blocks are called “trimmed” because they only contain half of the Vision Transformer (ViT) blocks used in the original ControlNet implementation. This controlling signal intercepts each of SDXL’s decoding stages and modifies their signal (sent to the next decoder block) by way of the green ZeroSFT connectors shown in the figure below. ZeroSFT stands for “zero-convolution, spatial feature transfer” and it connects the output from the encoder block (X_s in the green rectangle below), from the decoder block (X_f), and from the trimmed encoder copy (X_c) into the input for the next encoder block, as you can see in the figure here:
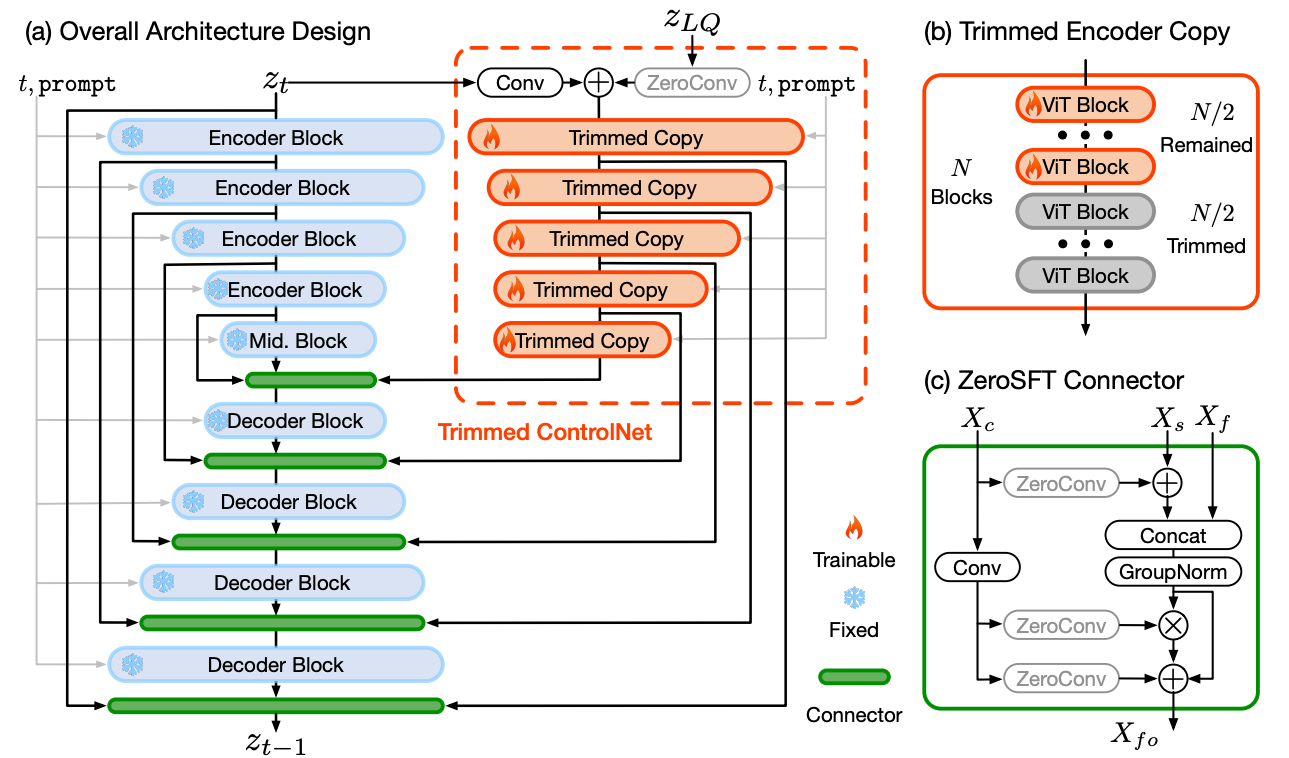
If that wasn’t enough, the authors found that ControlNet and the text prompt still aren't sufficient to control SDXL to generate images that are faithful to the low-quality input. They realized that this is because the beginning of the diffusion process is a bit like a blank book: SDXL has too much creative freedom. So, as a final controlling measure, the authors developed a restoration-guided sampling algorithm to guide the sampling process. The algorithm is a little complicated, but here’s the most important step:

In this equation, z_LQ is the encoded low-quality (LQ) image, z_t-1 is the partially diffused latent image that SDXL would have generated without the guidance, z_t is the latent image from the previous sampling step (t is counting downwards in these iterations), and k_t is the amount of noise in the image at step t compared to the beginning of the sampling process. The resulting value d_t is a weighted difference between z_t-1 and z_LQ, and it’s used to modify z_t to be more like z_LQ.
The term k_t is high at the start of the process, and decreases with time (as t goes down). This means that, in the beginning, the overall look of the low-quality image (encoded in z_LQ) dominates the look of the partially generated image-encoding z_t. But over time, the image encoding z_i (as i decreases) gains the freedom it needs to change the image for the better, and “remember” some of the earlier information from the input image.
The final part of the image-restoration puzzle is training data. The authors had to curate their own dataset of 20m high-fidelity images since there was no existing dataset that had enough high-quality images. The dataset includes, among others, 70k high-detail images of faces, and 100k negative-quality examples (as described above). To train the full system, which they call SUPIR, they synthetically degraded the training images and trained SUPIR on their restorations.
Evaluating SUPIR is tricky. A naive approach might be to try and match the restored images so that they’re as close to the original as possible. Metrics that do this are called full-reference metrics. There are other metrics, called non-reference metrics, that measure the quality based on the restored image only (not comparing it against the original). When compared to several other image-restoration baselines, the authors found that SUPIR often doesn’t perform best on the full-reference metrics, but it consistently performs best on the non-reference metrics. Let’s see some examples:

This figure shows the low-quality input on the left, the authors’ method on the far right, and the best performing baseline as measured by the full-reference metrics in the middle. For these full-reference metrics: Higher is better for PSNR and SSIM, but lower is better for LPIPS. While the middle column is preferred by these metrics, people typically prefer the images restored by SUPIR, a quality that’s reflected by the non-reference metrics.
There are some additional details in the paper about some of the ablation studies they performed, and a demonstration of how modifying the text prompt can guide the restoration process to a user’s preference, such as generating “messy fur” or “combed fur.” The paper’s webpage has many examples of SUPIR’s image-restoration results, which I encourage you to check out. One thing I wish the paper or webpage had done is compare restored images and the original, high-quality training images. It’s easy to pass off the restored images as good, but without seeing the originals it's hard to tell if SUPIR is inferring real details or just manufacturing plausible details. The authors haven’t released these models yet, but their GitHub page indicates that they plan to soon. When they do, I’d love to see something like this implemented in my browser so I can enhance images of pixelated text or low-quality JPEGs. That’d be super handy!