
Better language models with negative attention
[Paper: Differential Transformer]

Summary by Adrian Wilkins-Caruana
Sometimes I use ChatGPT or Gemini because I’m too lazy to read something. What I do is copy and paste pages upon pages of text into the system and then ask it a very specific question about the text, hoping that it will comprehend the text well enough to find the piece of information it needs to answer my question. As you can imagine, this isn’t straightforward for LLMs (or humans, either), so LLM researchers are constantly looking for ways to make LLMs better at this task, which they call “needle-retrieval” (from the idiom “to find a needle in a haystack”). Today’s summary is about a new needle-retrieval method called the differential transformer.

The differential transformer is a variant of the original transformer architecture, with the main difference being that this variant uses differential multi-head attention instead of the vanilla multi-head attention. In case you need a quick refresher, attention is a way for a neural network to weigh how important a pair of tokens in its input sequence is relative to all the other pairs. This weighting is what enables needle retrieval since the transformer can use strong weights to make connections between information about the needle and the needle itself. But, there’s a problem: Transformers tend to over-attend to irrelevant context (i.e., things in its context that aren’t the needle). The figure below shows this problem. The left bar chart shows the attention score for various tokens in the LLM’s context in a needle-retrieval scenario. We can see that the answer’s score isn’t that much more significant than the other context (unlike differential transformer in the middle chart, where it is much more significant).

You can think of differential attention as being kind of (but not quite) the difference between two attention heads. Each differential attention head learns a pair of query weights and a pair of key weights (as opposed to one each), and uses each pair to make a pair of query vectors and a pair of key vectors. In the first row of equations below, W^Q and W^K are twice as big as they would be in a vanilla transformer, and combining these with the input context yields the pairs of query (Q_1 and Q_2) and key (K_1 and K_2) vectors. The second row below shows how to use these to compute differential attention.
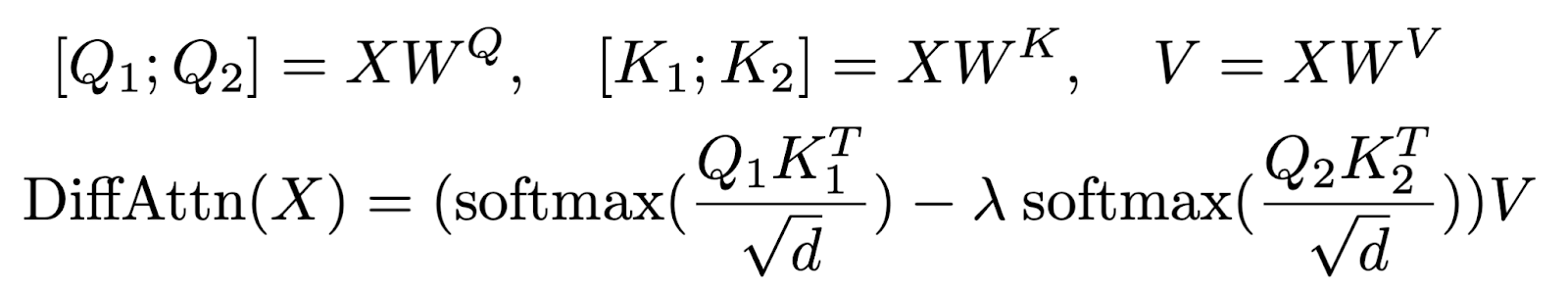
You might be thinking that doubling-up the queries and keys will make a differential transformer twice as large as a regular LLMs transformer, but no. The researchers find that a differential transformer only needs about half the amount of attention heads as a regular transformer, so they’re about the same size.
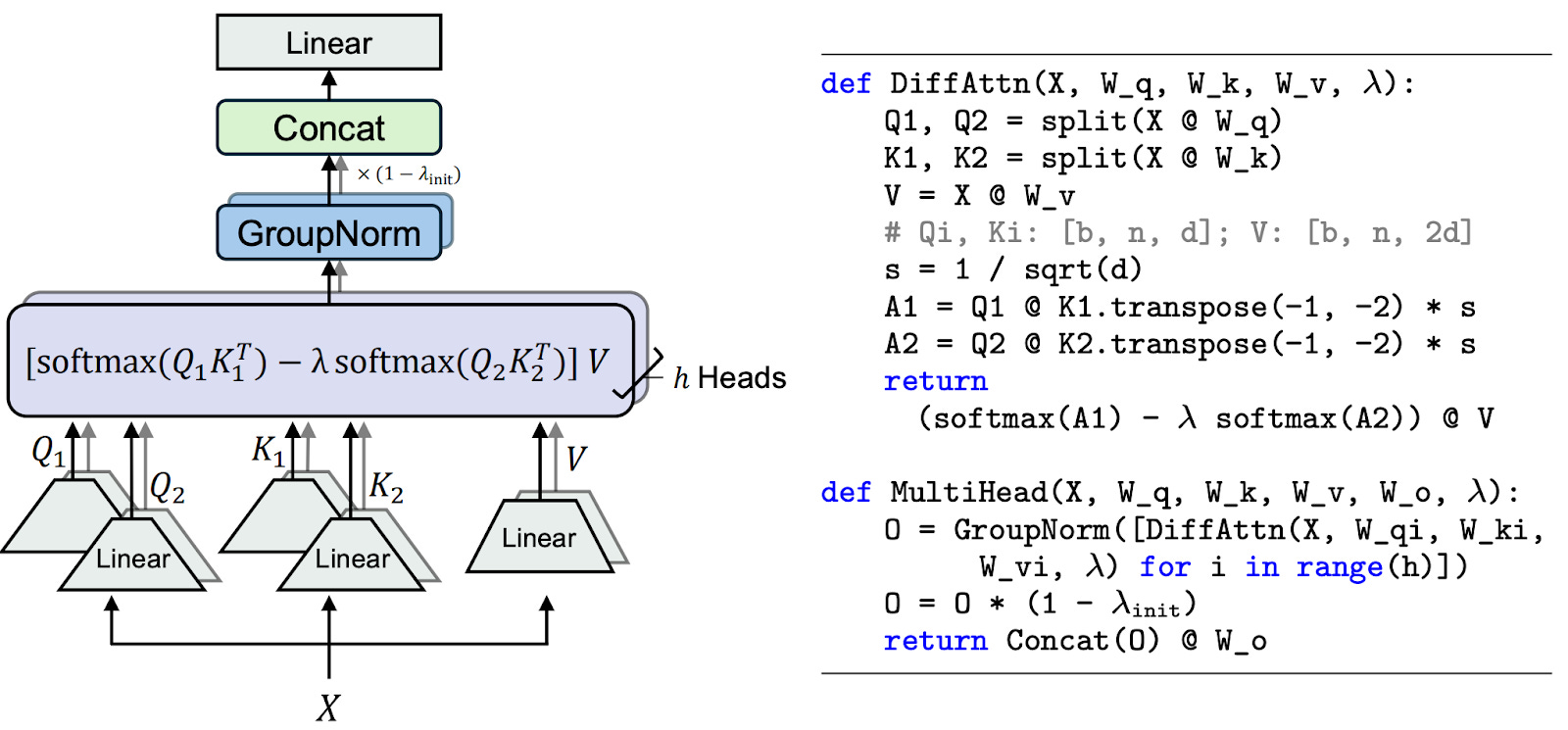
In case you’re wondering what the λ is in the equation above, it’s a learnable scaling factor that’s learned for each multi-head differential attention layer. The researchers proved that this formulation of differential attention (with the λ scaling factor) has similar gradient magnitudes during training as a regular transformer. The magnitudes differ by some constant factors, but neural network optimizers are invariant to such differences. The benefit of having similar gradient magnitudes is that training a differential transformer is identical to training a regular transformer (i.e., they can use the same hyperparameters). The figure below shows the multi-head differential attention architecture and the Python code for implementing it.
The figure below compares the differential transformer (right) to a regular one (left) in a multi-needle retrieval test. The horizontal axis denotes context length in thousands of tokens, and the vertical axis represents where in that context the needles are hidden. In the test, eight needles were hidden, but the LLM only needed to retrieve one needle to pass. The differential transformer had much more consistent needle-retrieval accuracy than the regular one across different depths and context lengths. The differential transformer is also much better at in-context learning, reaching accuracies 5% to 22% higher than a regular transformer in an in-context learning classification test. Finally, the researchers also found that differential transformers hallucinate less than regular ones, which is probably because they can more successfully find relevant information in their context to answer questions with (so they don’t have to resort to making stuff up).

The differential transformer architecture looks really promising, and I would be interested to see if new iterations of open-source LLMs, like Llama, adopt it. The tests that the researchers used (needle-retrieval, in-context learning, and hallucination rate) are ones that favor a model that’s really good at finding specific details in its context, but we don’t yet know whether this architecture is appropriate for general-purpose LLM and chat tasks. The researchers tested differential transformer’s general-purpose performance — it showed promise against other open-source architectures after training its 3B parameters with 1T tokens — but the jury is still out on whether this approach will scale to the 400B parameter, 15T token size of Llama 3.