
An elegant equivalence between LLMs and data compression
Paper: Language Modeling is Compression

Summary by Adrian Wilkins-Caruana and Tyler Neylon
Every time you send a text, upload a photo, or stream a song, it uses valuable resources like time, bandwidth, or storage space. But, because texts, images, and audio files contain lots of redundant information, they can be compressed to take up less space. Data compression has a peculiar link to machine learning: In 1948, Claude Shannon published a landmark paper that established the source coding theorem, which says that any compression method has a fundamental limit based on what’s called the entropy of the data set we’re compressing. In other words, there’s a smallest-possible average size that any given compression algorithm can possibly achieve based on the set of objects being compressed.
This limit — the entropy of the set being compressed — can also be seen as a measure of how predictable (or unpredictable) the set is. This idea of predictability is core to large language models, since they are trained to predict what’s next. But does that mean LLMs have been implicitly trained to be good at compressing things? Researchers from Google DeepMind put this theory into practice by testing the compression capabilities of LLMs.
Before we discuss how an LLM can be used to compress data, we need to talk about a general-purpose compression algorithm called arithmetic coding, which is a way to turn any sequence of symbols (such as letters) into a sequence of 0s and 1s that achieves near-optimal compression. Arithmetic coding works by knowing how likely each next symbol (e.g., next letter) is based on the symbols already present. The image below shows how the made-up string of letters “AIXI” would be converted into the binary sequence “0101010.” You don’t need to fully grok this image, but it can refresh your memory if you’ve learned about arithmetic coding before.

There are two important things to remember about the statistical model arithmetic coding uses for compression:
More accurate probabilities of the next symbol will allow the arithmetic coder to compress the data to a smaller size.
There’s an upper limit to how much the data can be compressed, and this limit is achieved when the probabilities are a perfect representation of the data. (This upper limit is the one described by Shannon’s source coding theorem.)
The title of this week’s paper, “Language Modeling is Compression,” foreshadows an important fact about how language models are trained. Specifically, LLMs are trained to output the probabilities of all possible next tokens based on the preceding tokens, which can be viewed as a conditional probability distribution. In other words, an LLM gives us exactly the probability information we would need to implement arithmetic coding, allowing us to achieve near-optimal compression (with Shannon’s theorem guaranteeing that it would be optimal if the probabilities were exactly right). However, the LLM will always have some degree of inaccuracy, so a compressor that uses the LLM’s model will always be suboptimal. The better the LLM’s model, the closer the compressor is to achieving the limit of optimal compression.
The team from Google DeepMind put this theory into practice by actually using LLMs to compress text, images, and audio. They use the LLM’s model of the data (i.e., its predicted probabilities of which tokens will appear next in the sequence) to compress data using arithmetic coding. When working with audio or image data, the LLMs they tested were treated as byte predictors, rather than token predictors. (If you’re curious, you can find the details of image/audio prediction from LLMs in the paper’s official github repo.) The authors measured two kinds of compression ratios: raw and adjusted. The raw compression ratio is the data’s compressed size divided by its original size. The adjusted compression ratio is the same, but the numerator includes the size of the model as part of the compressed data size, since the model would be needed to decode the compressed data if the compressor was used in practice.
The biggest LLM they used, Chinchilla 70b, achieved the best raw compression rates across the board, with 8.3% on text (meaning that the compressed size was 8.3% of the original size), 48.0% on images, and 21.0% on audio. These results are even better than purpose-built compressors for images (PNG) and audio (FLAC), which achieved 58.5% and 30.9%, respectively. This is an interesting result considering that the model was trained only on text from the internet, not on images and audio. The ability of an LLM to act as a general pattern machine (for non-text data) may be somewhat explained by this other paper.
Due to its huge size, Chinchilla 70b’s adjusted compression ratios are about two orders of magnitude greater than the original data size, making it impractical for use as a compressor (unless both the compressing and decompressing side have independent access to the same model). But smaller LLMs are quite effective compressors: A transformer with only 3.2m parameters trained on a Wikipedia dataset achieves better adjusted text compression (17.7%) on the same dataset than the general-purpose compressors gzip (32.3%) and LZMA2 (23.0%).
The optimal relationship between model size and compression rate depends on the size of the data being compressed, as shown in the figure below. Bigger, more complex datasets can afford to use larger models. (The names enwik7, enwik8, and enwik9 refer to three natural language files from a snapshot of Wikipedia, with enwikX representing the first 10^X bytes. So, for example, enwik8 is the first 100 million bytes of the English Wikipedia data dump.)
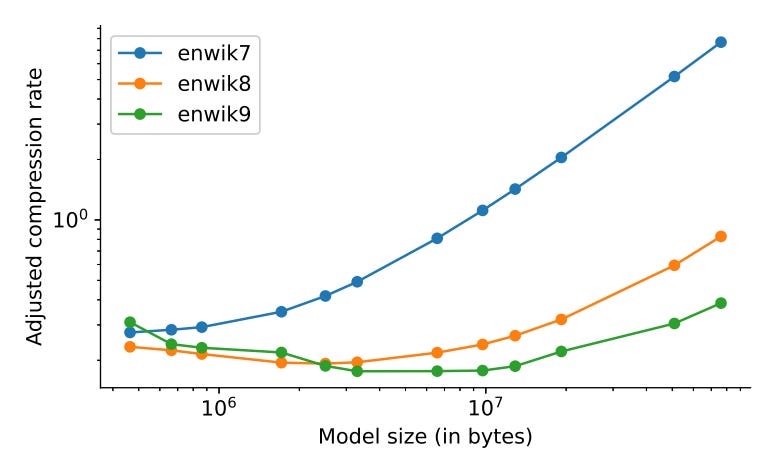
My biggest take-away from this paper is that the lens of compression helps us understand the relationship between an LLM’s size and how it scales in other ways. Bigger models may be slightly better predictors, but scaling such a model yields diminishing returns, and these returns can be understood by taking the model size into account. Using this approach, we can establish an “optimal” model size, one which takes into account the dataset size (like in the figure above) to inform model size choices.