
AI + fMRI = reading minds (with music)
Paper: Brain2Music: Reconstructing Music from Human Brain Activity

Summary by Adrian Wilkins-Caruana
Close your eyes and imagine “popcorn.”
When I do this, the neurons in my brain fire in a way that, to me, means “the smell of buttery, salty popcorn at the cinema.” Likewise, when an LLM “imagines” popcorn, the model’s artificial neurons that correspond to things like salt, butter, and the cinema might also activate. Does this mean that human brains and artificial ones think the same way? Today’s paper sheds some light on this topic — specifically, whether human brains and artificial ones think about music in similar ways.

If you called me and asked me to sing to you (which I wouldn’t recommend ), the sound of my voice would be converted into a different format, one that can be transmitted over wires or electromagnetic waves, before it’s then reconstructed into sound you can hear from your phone. This new research from Google is trying to do a similar thing: It’s trying to “listen” to what people perceive when they actually listen to music. The “microphone” is an fMRI machine, which records the brain activity, and the “speaker” is MusicLM, a neural network that generates digital audio that can be played by speakers.
In this analogy, the transmission mechanism is a linear mapping: It converts the fMRI brain measurements into something that MusicLM can understand. If the mapping is perfect, then we might expect to hear exactly what the subject hears. If it’s less good, then we might only hear the same genre that the subject is listening to. And, if it’s no good at all, then there might not be any correlation between what the subject hears and what we hear. This figure shows the process:
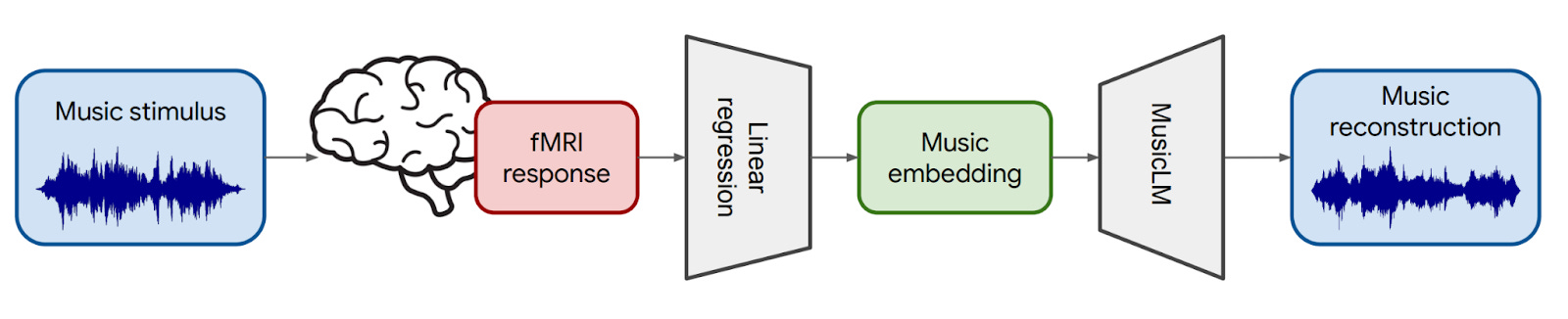
Unfortunately, MusicLM is a text-to-music model, not an fMRI-to-music model. In order for MusicLM to “listen” to the fMRI brain activity response, the response needs to be converted into something that MusicLM can understand. Instead of mapping the brain activity to text, the authors choose to map it to a music embedding space called MuLan. The fMRI response and MuLan embeddings are both very large sets of numbers, so the authors trained a linear regressor to predict MuLan embeddings from fMRI, and then used the trained regressor to predict new MuLan embeddings when the subject listened to more music. The authors found that this was the best way to map fMRI activity into something a music neural network can understand.
MusicLM understands the musical vector space defined by MuLan, so it can reconstruct audio from those vectors. But MusicLM also needs semantic audio tokens, which are trained from text representations such as “A hip hop song with a violin solo.” Since the researchers were mapping from fMRI, they trained a mapping of MuLan embeddings to MusicLM tokens, which are clustered activations from the 7th layer of a word2vec (w2v) BERT LLM. Then, since MusicLM is a conditional music generation model, it conditions on the MuLan embeddings using cross-attention to convert these tokens into CoDec SoundStream tokens, which — finally — can be converted back into music!

The researchers found that this method can’t generate perfect reconstructions of the music the subjects listen to, but, empirically, it can reconstruct the genre! For example, MusicLM generates pop-sounding music when the subject is listening to “Oops!…I Did It Again” by Britney Spears. Interestingly, the reconstructed vocals are mostly incomprehensible, and yet they sound like English. The result reminds me of Prisencolinensinainciusol, a nonsense song by Italian singer Adriano Celentano that mimics the sound of American English.
It’s fun to listen to some of the reconstructed music samples, and this method offers a new tool for investigating how the brain works. Essentially, they can run MusicLM in reverse to predict the brain activity of a subject based on audio-derived MuLan embeddings and MusicLM tokens. Compared to MusicLM’s w2v-BERT embeddings, the MuLan embeddings were much more predictive of activity in the prefrontal cortex. The researchers think that this is because MuLan captures high-level information that’s more correlated with the high-level functioning prefrontal cortex. They also found that w2v-BERT and MuLan embeddings are equally predictive of activity in the auditory cortex.
After reading this paper, I’m amazed by the similarities between human brains and artificial ones, and fascinated by how differently we learn and function. Unlike LLMs, children can learn to read without being exposed to a trillion tokens (or ~7.5M books). My parents only needed to take me to the cinema once before I learned to associate the smell of popcorn with seeing a film. And, without any training examples at all, I already know you should never call me and ask me to sing you a song.
For the time being, it seems that human brains and artificial ones are not the same.