
A surprising, simple way to fight underfitting
Spoiler: It's dropout.

The basic idea of dropout is simple: When training a model, you randomly “turn off” certain neurons; they simply don’t fire. What’s been well-known for a while is that this can help reduce overfitting, which is when a model performs well on its training data, but poorly on its test data. Intuitively, overfitting happens when a model has memorized some flash cards but can’t extrapolate to a new flash card.

I didn’t grok dropout until I watched a lecture series on YouTube by Geoffrey Hinton. This short video in particular is great: Dropout helps improve models by forcing individual neurons to make good independent contributions of information. With dropout, neurons avoid depending on spikes from one or two key neurons to do all the work, because those neurons will randomly be turned off during training.
It’s like working on a group project, but randomly half your team won’t show up each day — this forces every team member to be able to contribute something.
The opposite problem is underfitting, when a model continues to do poorly on training data. This is analogous to a student who tries to jump to general conclusions, but keeps getting it wrong. A kid might think that since “2x2=4,” we can guess “multiplication is the same as addition.” Sometimes a model underfits because it doesn’t have the information capacity. But in some cases, it does have the capacity, but it’s difficult to get from a state of random weights (which is where we begin), and scooch on over to a state of weights that begin to usefully pull out key features from the training set.
Today’s paper explains the new discovery of how these two worlds meet.
— Tyler & Team
Paper: Dropout Reduces Underfitting
Summary by Adrian Wilkins-Caruana
For many years, researchers have dealt with the problem of overfitting (when a neural network (NN) is big enough to memorize some its training data and gets worse at generalizing to unseen data) by using a technique called dropout, which involves randomly turning off particular NN weights during training. These days, training sets have gotten so huge that their growth has outpaced model growth, and researchers are now grappling with the opposite issue: underfitting, where NNs struggle to remember enough training data. Fortunately, Liu et al. have discovered that dropout can help with underfitting, too!
Specifically, dropout helps to prevent underfitting early in the training process. Training is kind of like trying to walk toward a door in the dark: you don’t know where the door is, but you’re guided by several dubious clues (imperfect gradients from mini-batches) along the way. When you train with dropout, the NN puts less emphasis on each individual clue, which means it takes smaller but more accurate steps towards the “door” (whole-dataset generalization). This is really helpful when you start walking, since taking a big step in the wrong direction can put you farther from the door, which leads to underfitting!
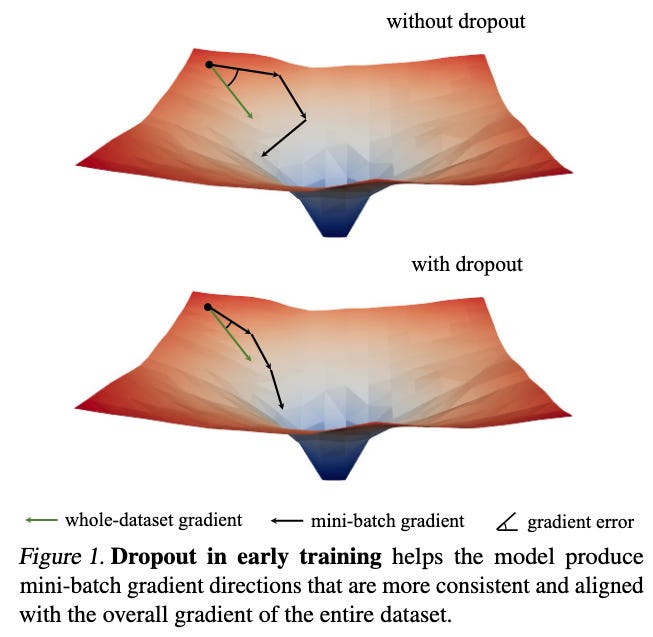
To figure this out, Liu et al. computed something called the Gradient Direction Error (GDE), which measures the difference between mini-batch gradients (dubious steps) and whole-dataset gradients (perfect steps towards generalization). Using dropout early in training results in more accurate steps (lower GDE). But, after a certain point, using dropout results in worse step-taking. This means researchers have to make a decision: should they use dropout to prevent overfitting or underfitting?

The answer depends on whether a particular model and dataset are more prone to underfitting or overfitting. If a model-data combination performs better with dropout, then it’s prone to overfitting and, to prevent that, we should only use dropout towards the end of training; this is called late dropout. If it performs better without dropout, then that means it’s prone to underfitting and, to prevent that, we should only use dropout at the start of training — early dropout!
This image shows how turning off dropout at different points during training increases a model’s maximum accuracy. Turning off dropout anywhere between the 5th and 300th epoch helps reduce underfitting.
